im钱包安装下载|以太坊挖矿算法
作者: im钱包安装下载
2024-03-14 02:39:45
加密货币十六:ETH的挖矿算法 - 知乎
加密货币十六:ETH的挖矿算法 - 知乎首发于区块链基础知识切换模式写文章登录/注册加密货币十六:ETH的挖矿算法力所能及后端开发,人在深圳;更进一步,达成目标。挖矿这一过程,虽然并没有创造什么实际价值,但挖矿本身维持了系统的稳定。前面说到比特币系统的挖矿算法存在一个问题,挖矿设备ASIC芯片的专业化导致普通计算机用户难以参与。导致了挖矿中心化的局面产生,而这与“去中心化”这一理念相违背。因此,包括以太坊在内的许多加密货币进行ASIC Resistance(抗拒专用矿机)。由于ASIC芯片相对普通计算机来说,算力强但访问内存性能差距不大,因此常用的方法为Memory Hard Mining Puzzle,即增加对内存访问的需求。莱特币在介绍以太坊抗ASIC设计之前,我们先介绍一下莱特币的设计思路:莱特币的puzzle基于Scrypt。Scrypt为一个对内存性能要求较高的哈希函数,之前多用于计算机安全密码学领域。因为哈希函数的输出并不能提前预料,所以看上去就像是一大堆随机的数据,因此称其为“伪随机数”。设置一个很大的数组,按照顺序填充伪随机数。Seed为种子节点,通过Seed进行一些运算获得第一个数,之后每个数字都是通过前一个位置的值取哈希得到的,这样的数组中取值存在前后依赖关系。在需要求解Puzzle的时候,按照伪随机顺序,从数组中读取一些数,每次读取位置与前一个数相关。例如:第一次,从A位置读取其中数据,根据A中数据计算获得下一次读取位置B;第二次,从B位置读取其中数据,根据B中数据计算获得下一次读取位置C;如果数组足够大,对于挖矿矿工来说,必须保存该数组以便查询,否则每次不仅计算位置,还要根据Seed计算整个数组数据,才能查询到对应位置的数据。这对于矿工来说,计算复杂度大幅度上升。当然,矿工可以选择只保存一部分数据,例如:只保存奇数位置数据,偶数位置需要时再根据前一个奇数位置数据计算即可,从而对内存空间大小减少了一半(计算复杂度提高一点,但内存减少一半)。核心思路:除了进行运算,还要增加其对内存的访问,从而实现对ASIC芯片不友好。但实际中,莱特币系统设计的数组大小仅仅128K大小。是因为该设计方法对Puzzle验证并不是很友好,想要验证该Puzzle,也需要存储该数组,因此对于系统中占绝大多数的轻节点来说,数组要小才好。但莱特币的设计并未起到预期作用,也就是说,128k对于ASIC Resistance来说过小了。此外,莱特币和比特币另一区别为出块时间,莱特币为2.5min,为比特币的1/4。除了这些不同外,这两种货币基本一样。以太坊挖矿算法基本思想以太坊的理念与莱特币相同,都是Memory Hard Mining Puzzle,但具体设计上与莱特币不同。以太坊中,设计了两个数据集,一大一小。小的为16MB的cache,大的数据集为1G的dataset(DAG),1G的数据集是通过16MB数据集生成而来的。(注:以太坊中这两个数组大小并不固定,因为考虑到计算机内存不断增大,因此该两个数组需要定期增大)为何要设计一大一小两个数据集?为了便于进行验证,轻节点保存16MB的Cache进行验证即可,而矿工为了挖矿更快,减少重复计算则需要存储1GB的大数据集。16MB的Cache数据生成方式与莱特币中生成方式较为类似:通过Seed进行一些运算获得第一个数,之后每个数字都是通过前一个位置的值取哈希获得的大的DAG生成方式:大的数组中每个元素都是从小数组中按照伪随机顺序读取一些元素,方法同莱特币中相同。如第一次读取A位置数据,对当前哈希值更新迭代算出下一次读取位置B,再进行哈希值更新迭代计算出C位置元素。如此来回迭代读取256次,最终算出一个哈希值作为DAG中第一个元素,如此类推,DAG中每个元素生成方式都依次类推。cache与DAG的关系求解puzzle,即以太坊挖矿过程:根据区块block header和其中的Nonce值计算一个初始哈希,根据其映射到某个初始位置A1,读取A1位置的数及其相邻的后一个位置A2上的数,根据该两个数进行运算,算得下一个位置B1,读取B1和B2位置上的数,依次类推,迭代读取64次,共读取128个数。最后,计算出一个哈希值与挖矿难度目标阈值比较,若不符合就更换Nonce,重复以上操作直到最终计算哈希值符合难度要求(注意有可能当前区块已经被挖出)。伪代码理解以太坊挖矿算法目前以太坊挖矿以GPU为主,可见其设计较为成功,这与以太坊设计的挖矿算法(Ethash)所需要的大内存具有很大关系。1G的大数组与128k相比,差距8000多倍,即使是16MB与128K相比,也大了一百多倍,可见对内存需求的差距很大(况且两个数组大小是会不断增长的)。当然,以太坊实现ASIC Resistance除了挖矿算法设计之外,还存在另外一个原因,即其预期从工作量证明(POW)转向权益证明(POS)。权益证明:按照所占权益投票进行共识达成,类似于股份制有限共识按照股份多少投票,权益证明不需要挖矿。而这对于ASIC矿机厂商来说,就好比一把悬在头上的达摩克利斯之剑。因为ASIC芯片研发周期很长,成本很高,如果以太坊转入权益证明,这些投入的研发费用将全部白费。但实际上,以太坊目前仍然是POW挖矿共识机制。在设计之初,以太坊开发者就设想要从POW转向POS,并为了防止有矿工不愿意转埋下了一颗“难度炸弹”。但截至目前,以太坊仍然基于POW共识机制。预挖矿(Pre-Mining)以太坊中采用的预挖矿的机制。这里“预挖矿”并不挖矿,而是在开发以太坊时,给开发者预留了一部分货币。以太坊的早期开发者,目前就很有钱了。和Pre-Mining对应,还有Pre-Sale,Pre-Sale指的是将预留的货币出售掉用于后续开发,类似于拉风投或众筹。目前,各类加密货币很多,存在一部分货币就在采用Pre-Sale来获取资金,如果此时买入,后续如果该货币取得成功,同样可以获得很大收益,但真正成功的货币只占少数,这就是其风险性。以太坊总供应量:饼状图中,蓝色部分都是Pre-Mining产生的(接近3/4),可见掌握技术有多么重要。黑色部分为出块奖励产生的以太币,绿色为叔父区块产生的奖励以太币。另一角度也有人认为让普通计算机参与挖矿是不安全的,像比特币那样,让中心化矿池参与挖矿才是安全的,为什么呢?如果让通用计算机也参与挖矿,发动攻击成本便大幅度降低,目前的大型互联网公司,将其服务器聚集起来进行攻击即可,而攻击完成后这些服务器仍然可以转而运行日常业务。因此,也有人认为,在挖矿上面,ASIC矿机“一统天下”才是最安全的方式。编辑于 2021-07-26 18:11赞同 22 条评论分享喜欢收藏申请转载文章被以下专栏收录区块链基础知
ETHASH 挖矿算法 — 以太坊的指南针 1.0.0 documentation
ETHASH 挖矿算法 — 以太坊的指南针 1.0.0 documentation
以太坊的指南针
目录
如何学习这本书
第 1 章 以太坊:一台全球计算机
简史
发展阶段
以太坊的特色
第 2 章 账户是什么
小白基础知识问答
我的以太币记录在哪里?
我的以太币余额如何变化?
什么是区块?
区块和状态的关系
“巨大的账本”
我如何参与以太坊?
我如何与其他人同步账本?
账户探秘
账户与账户状态
账户状态的内涵
已执行交易总数
持币数量
存储区的哈希值
代码区的哈希值
没有钱包App, 如何生成账户?
智能合约地址的生成
扩展阅读
资料篇:Keystore 与私钥保存
资料篇:常用钱包 App
资料篇:EIP-55 格式的账户地址
第 3 章 交易是驱动力
交易的发送
交易与消息的区别
交易的特性是什么?
交易的样子
交易的生命周期
扩展阅读
资料篇:共识与工作量证明
比特币的PoW机制(简单版)
比特币算力的中心化问题
以太坊的Pow/Pos机制
资料篇:矿工与挖矿奖励
第 4 章 数据结构
Radix树
Merkle树和 Merkle证明
Merkle Patricia树
RLP编码
RLP字符/字符串编码
RLP字符/字符串解码
RLP数组编码
RLP数组解码
扩展阅读
资料篇:状态树 (以及存储树)
资料篇:交易树
资料篇:收据树
资料篇:区块
第 5 章 构建一条以太坊私链
安装
Geth客户端的结构
启动一条以太坊私链
接收挖矿奖励
转账与收款
第 6 章 手把手教你部署智能合约
什么是智能合约?
安装编译器
Solc编译智能合约
智能合约发布准备
部署智能合约
调用智能合约
第 7 章 以太坊虚拟机探秘
虚拟机的执行结果
虚拟机的执行资源
合约调用合约?
虚拟机的输入输出
Gas 花费与退回
虚拟机指令集
第 8 章 Solidity语法练习
基础概念
没有浮点数运算
合约基础
变量类型
运算符号
结构体 Struct
数组array
函数申明
类型转换与内置函数
合约与事件
语法进阶
数据结构:map
环境变量:msg.sender
require还是assert?
继承和引入
省钱妙招:内存变量
接口与合约调用
多返回值
高级语法和概念
Contract 构造函数
Ownable控制
Pausable控制
省钱妙招:struct 结构体
时间单位表达
带参数的函数修饰符
for 循环
合约收款:payable修饰符
支付费用:transfer方法
小结
第 9 章 Truffle合约开发实战
编译、测试工具安装
Truffle的安装
Ganache的安装
Truffle启动样例项目
下载样例
编译项目
部署项目到 Ganache
测试项目
上手实践:ERC20合约
新建项目目录
ERC20 Basic合约接口
ERC20 合约接口
SafeMath基础数学库
猫币:CAT数字资产合约
上手实践:ERC20合约测试
准备工作
测试辅助函数与库
测试代码分析
测试运行与结果
附录 有意思的冷知识
短地址攻击
比特币的区块
以太坊与比特币账户的区别
隐私与安全性的比较
数据体积与并发能力
发送交易时对双花的处理
“不可能的三角”问题
ETHASH 挖矿算法
ETHASH和比特币PoW的异同
ETHASH的设计目标
ETHASH的挖矿运行总流程
ETHASH算法源代码解读
以太坊的指南针
»
附录 有意思的冷知识 »
ETHASH 挖矿算法
Edit on GitHub
ETHASH 挖矿算法¶
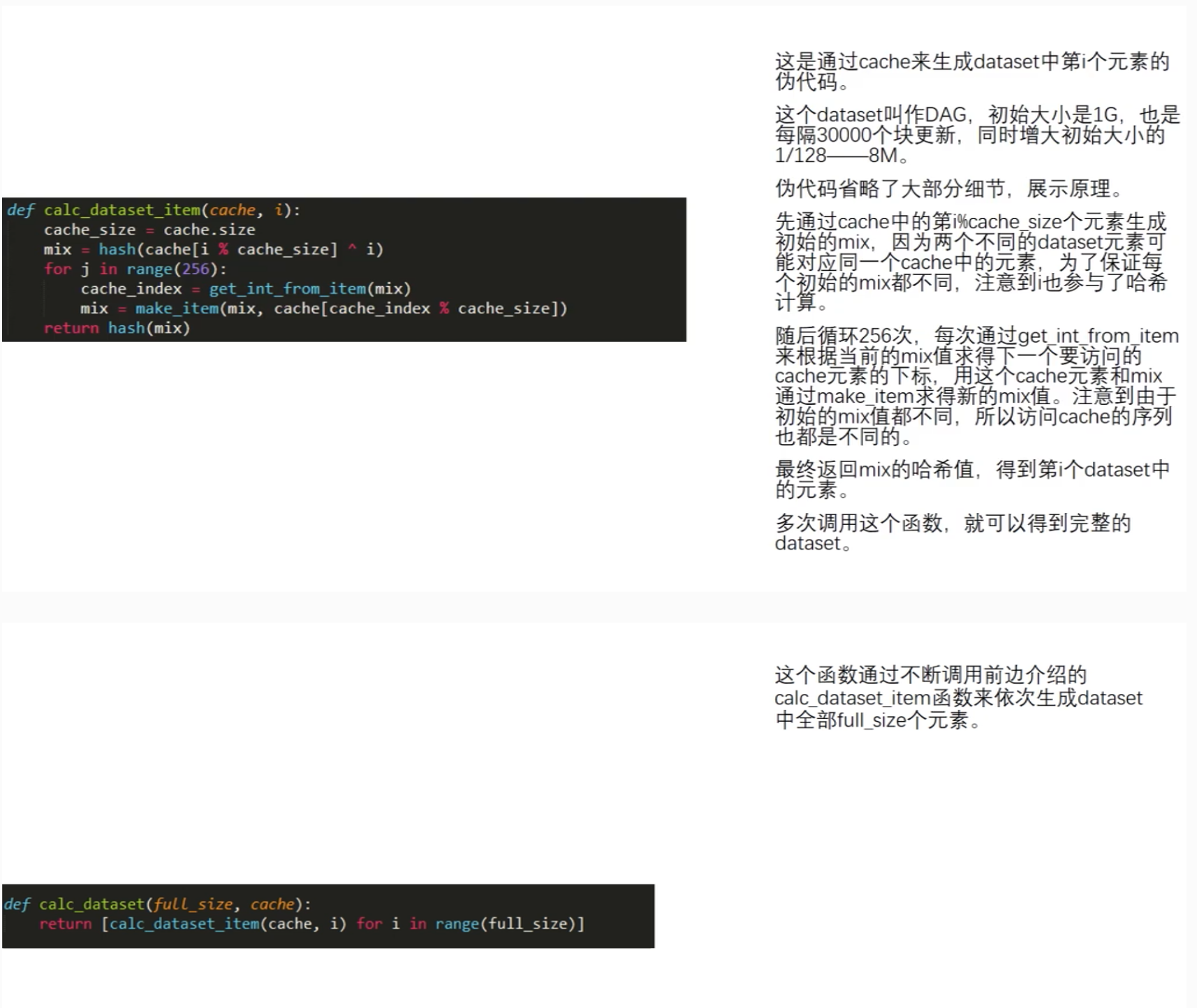
把最好的东西留到最后品尝,本书将以太坊的PoW(Proof of work)挖矿算法核心ETHASH算法作为最好的礼物留到最后讲解。掌握了ETHASH算法我们就有能力进行新的、独立的公链开发。这个知识也是最难消化的,需要读者有许多相应的数学知识背景。请让我们一步一步来对照着源代码讲解这部分知识。
ETHASH和比特币PoW的异同¶
ETHASH这个算法是消耗资源的PoW模式,同比特币共识算法一样,它需要消耗大量的计算资源得出最终的“结论”。但是这个结论的得出和执行交易的顺序无关。也就是说一般情况下并非需要调整“交易的排列组合”来影响最终的哈希计算值结果符合“阈值”的标准。这点和比特币是完全不一样的。在交易序列唯一确定后,以太坊共识算法通过调整8字节(64bit)的nonce值来让计算最终结果符合“阈值”的要求。
ETHASH的算法更加依赖于CPU+内存的双料资源组合,比特币的SHA256算法仅仅依赖于CPU的资源,两者在挖矿公平性上也是不同的,这点在后文会有讲解。
ETHASH的设计目标¶
在比特币诞生之后经历了很长一段时间,开源社区发现仅依赖于CPU的计算的算法造成挖矿成功率向算力高的一方倾斜,并诞生出了诸如矿机这种专门的设备用于挖矿。矿机并不是一台完整的计算机,而是利用如ASIC集成电路、GPU、FPGA等专用电路进行并发操作。获得更高的多挖矿效率。这个趋势渐渐将普通人的电脑淘汰出挖矿的队伍,让话语权集中于数个矿场主手中。有违背于区块链公链“人人参与,去中心化”的精神,对区块链的分布式安全也是严重的威胁。在后世的算法设计中,就将装备了“慢CPU”的设备也能参与进挖矿定为一个重要的设计目标。PoW挖矿算法更多地让整台计算机资源都充分被利用,例如GPU、内存等设备,将单纯提高CPU的优势抹平。
ETHASH并非一日铸成,前身经历了两次演进/组合,前身称之为Dagger-Hashimoto算法。Dagger与Hashimoto是两个不同的算法,它们共同组合起来形成了一套“Memory Hard Function”也就是对内存要求较高的计算/验证算法。它的核心点就是要找到一个8字节(64bit)的nonce值。而这个随机数的产生,没有比枚举更好的策略,这样对于每个挖矿者而言,找到随机数的概率是公平的。而这个随机数的找到的概率,取决于预先设置的挖矿难度。难度越高,找到随机数的概率越小,则同样的挖矿者需要更长时间来搜寻。这让以太坊有通过设置挖矿难度动态调整出块时间的可能。我们现在习惯的15秒出一个以太坊的块,就是动态难度调整和世界千万挖矿者算力博弈的最终动态平衡。
ETHASH的挖矿运行总流程¶
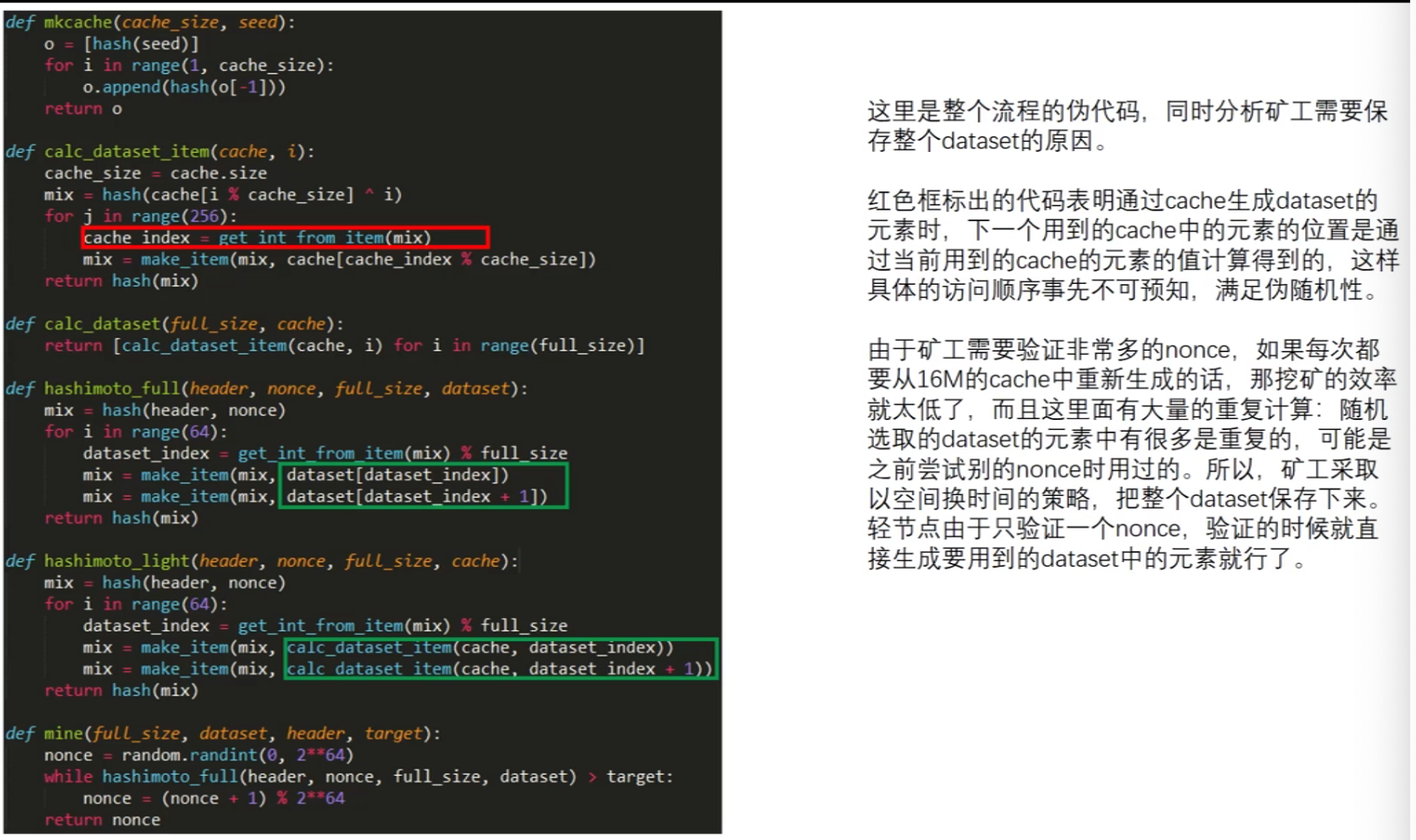
ETHASH改良了Dagger-Hashimoto,正确的说已经脱胎换骨,和原来的算法已经面目全非。它的总算法分为DAG的生成和DAG的使用(挖矿)两个部分。它有效地解决了单纯内存依赖的算法诸如Scrypt算法加密难与解密同样难的困境,也突破Dagger算法不抵抗内存共享硬件加速的困境,从全区块链数据的生成改为固定的1GB的数据的生成,支持了客户端预生成数据,保障挖矿难度的平滑过度。
总的工作量/工作量证明总体流程如下。
计算一个种子(Seed),该种子的计算依赖于当本块及本块之前的所有块。
从种子中计算得出一个缓存(Cache),该缓存仅仅由种子得出,是一个16MB大小的数据集。轻客户端应存储下该缓存用于日后验证。
从缓存中生成一个1GB大小的数据集(DataSet),这个数据集通常称为DAG。完整客户端或者挖矿客户端需要保存该1GB大小的数据,该数据随时间线性增长。
挖矿过程即为哈希过程。哈希的输入是取得1GB数据集的数个子部分,并将它们放在一起执行哈希。验证过程是可以在轻客户端通过Cache缓存生成被挖矿制定的数据碎片并执行哈希验证。故而轻客户端并不需要时刻保存1GB的DAG。
每当30000个以太坊区块被发掘后,1GB的数据集将被更新一次,所以矿工的主要精力放在读取这个数据集上,而非产生数据集。为了平滑过度30000个时间点上的DAG产生带来的延迟,可以预先生成DAG数据。
ETHASH算法源代码解读¶
我们之前探讨的算法都是纸上谈兵。接下去我们将分段用Go语言源码 方式来查看一下究竟ETHASH的挖矿和验证过程是如何进行的。探讨挖矿过程就如同探索爱丽丝仙境中的兔子洞,必须层层向下探索,它的最终解答的问题是:如何才能用ETHASH算法找到一个合法的nonce,进而形成一个块?
整个打包块的过程源于sealer(封装)函数,它需要负责封装一个合法的块,这个块的获得将是一个mine(挖矿)过程,我们来查看一下它们的函数签名。
/consensus/ethash/sealer.go¶
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{}) error {
Seal函数总目标是找到一个nonce,让其符合块难度设定,这样块就能成为合法的块而被其他节点所接受。接受多个参数输入,并返回一个Ethash的指针。输入参数中包含了ChainReader,可料想到对于区块链前置的数据是有扫描的;Block可见最终也会修改块的部分数据,例如头部数据。我们来查看一下Ethash数据结构是怎样的:
/consensus/ethash/ethash.go¶
type Ethash struct {
config Config
caches *lru // LRU类型的Cache缓存避免大量反复查询
datasets *lru // LRU类型的 DataSet数据集,防止反复生成
// 挖矿相关
rand *rand.Rand // 产生nonce的随机数
threads int // 挖矿需要的线程数量
update chan struct{}
hashrate metrics.Meter // 跟踪当下hash rate挖矿效率的参数
// 远程打包者所关注的参数
workCh chan *sealTask // 通知渠道,通知远程打包者打包数据
fetchWorkCh chan *sealWork // 获取渠道, 远程打包者获取元数据
submitWorkCh chan *mineResult // 提交渠道,远程打包者提交打包结果
fetchRateCh chan chan uint64 // 获取渠道,获取远程打包者提交挖矿效率参数值
submitRateCh chan *hashrate // 提交渠道,远程大包着提交挖矿效率参数值
// 用于测试的钩子
shared *Ethash
fakeFail uint64
fakeDelay time.Duration
lock sync.Mutex
closeOnce sync.Once
exitCh chan chan error
}
我们看到了熟悉的三个元素,caches、datasets、rand,这三个参数在之前的算法粗略讲解里面已经提到,是ETHASH的所使用到参数的基石,我们看下这个具体的封装区块的过程。
/consensus/ethash/sealer.go¶
// Seal函数主要功能是触发miner函数进行挖矿操作
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{}) error {
// 为了简洁,我们删去了测试代码
// 为了简洁,我们删去了共享挖矿的代码
// 取消挖矿信号量
abort := make(chan struct{})
ethash.lock.Lock()
threads := ethash.threads
if ethash.rand == nil { // 产生一个可靠的随机数
seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64))
if err != nil {
ethash.lock.Unlock()
return err
}
ethash.rand = rand.New(rand.NewSource(seed.Int64()))
}
ethash.lock.Unlock()
if threads == 0 {
threads = runtime.NumCPU()// 决定多少并发挖矿线程
}
if threads < 0 {
threads = 0 // 取消本地挖矿功能
}
// 将挖矿过程推送给远程挖矿者
if ethash.workCh != nil {
ethash.workCh <- &sealTask{block: block, results: results}
}
var (
pend sync.WaitGroup
locals = make(chan *types.Block)
)
for i := 0; i < threads; i++ {
pend.Add(1)
go func(id int, nonce uint64) { // 最重要的函数,etash.mine为挖矿函数
defer pend.Done()
ethash.mine(block, id, nonce, abort, locals)
}(i, uint64(ethash.rand.Int63()))
}
// 开启多线程,直到挖矿成功或者取消挖矿
go func() {
var result *types.Block
select {
case <-stop:
// 外部取消信号捕捉,直接关闭挖矿线程
close(abort)
case result = <-locals:
// 某一线程找到了合法块,通知其他挖矿线程关闭
select {
case results <- result:
default:
log.Warn("Sealing result is not read by miner", "mode", "local", "sealhash", ethash.SealHash(block.Header()))
}
close(abort)
case <-ethash.update:
// 重启所有挖矿线程
close(abort)
if err := ethash.Seal(chain, block, results, stop); err != nil {
log.Error("Failed to restart sealing after update", "err", err)
}
}
// Wait for all miners to terminate and return the block
pend.Wait()
}()
return nil
}
我们看到上文中大部分代码都在处理多线程关系,还有挖矿的开启和停止,用到了Go语言的核心功能–多线程并发。挖矿的代码就一行,是一个调用,调用了ethash.mine(block, id, nonce) 这个子函数进行真的苦力活PoW算法,下面我们查看一下这个具体挖矿的实现代码。
/consensus/ethash/sealer.go¶
// 通过PoW挖矿行为找到最终符合条件的nonce值
func (ethash *Ethash) mine(block *types.Block, id int, seed uint64, abort chan struct{}, found chan *types.Block) {
// 从区块头部获取必要的信息
var (
header = block.Header()
hash = ethash.SealHash(header).Bytes()
target = new(big.Int).Div(two256, header.Difficulty)
number = header.Number.Uint64()
dataset = ethash.dataset(number, false)
)
// 开启反复试算nonce值,直到算出,或者取消。
var (
attempts = int64(0)
nonce = seed
)
logger := log.New("miner", id)
logger.Trace("Started ethash search for new nonces", "seed", seed)
search:
for { // 死循环开始
select {
case <-abort:
// 如果我们取消了,停止
logger.Trace("Ethash nonce search aborted", "attempts", nonce-seed)
ethash.hashrate.Mark(attempts)
break search
default:
// 记录尝试次数
attempts++
if (attempts % (1 << 15)) == 0 {
ethash.hashrate.Mark(attempts)
attempts = 0
}
// 重要! 试算PoW算式下的nonce值
digest, result := hashimotoFull(dataset.dataset, hash, nonce)
// 重要! 成功找到nonce值的判定标准!
if new(big.Int).SetBytes(result).Cmp(target) <= 0 {
// 更新header,试算结束!
header = types.CopyHeader(header)
header.Nonce = types.EncodeNonce(nonce)
header.MixDigest = common.BytesToHash(digest)
// 成功找到块打包结束
select {
case found <- block.WithSeal(header):
logger.Trace("Ethash nonce found and reported", "attempts", nonce-seed, "nonce", nonce)
case <-abort:
logger.Trace("Ethash nonce found but discarded", "attempts", nonce-seed, "nonce", nonce)
}
break search
}
nonce++
}
}
runtime.KeepAlive(dataset)
}
在上方的代码中,总逻辑是一个死循环,循环内部反复试算nonce值直到符合难度规定,那么判断的条件就是一个依据,如下面这行代码所示。
if new(big.Int).SetBytes(result).Cmp(target) <= 0 {
这句话至关重要,如果试算出来的结果result小于target,则试算成功。那么又是如何试算的呢?我们仔细看可以看到这么一个试算函数。
digest, result := hashimotoFull(dataset.dataset, hash, nonce)
/consensus/ethash/algorithm.go¶
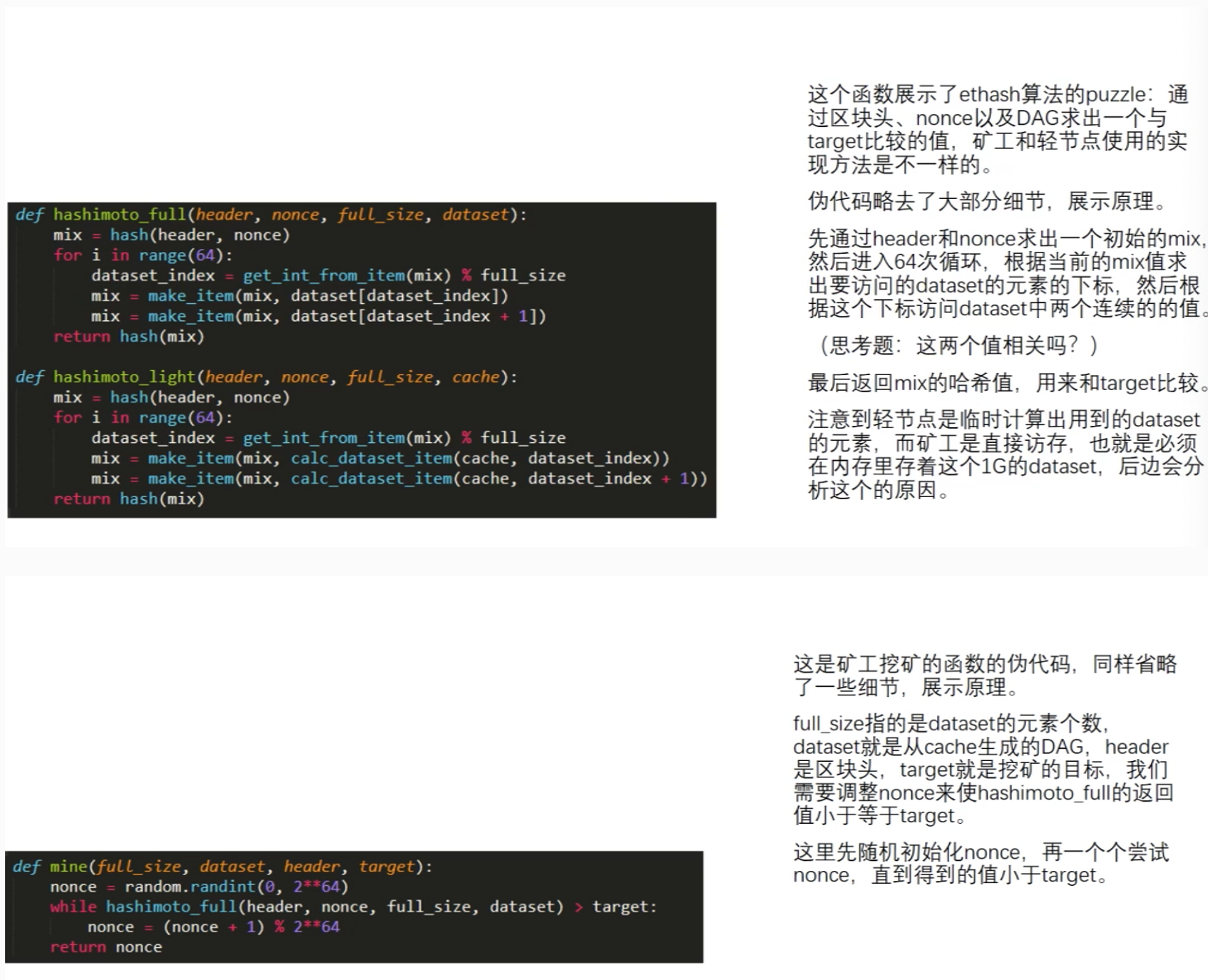
func hashimotoFull(dataset []uint32, hash []byte, nonce uint64) ([]byte, []byte) {
lookup := func(index uint32) []uint32 {
offset := index * hashWords
return dataset[offset : offset+hashWords]
}
// 将具体的hashimoto算法触发,获得最终的结果
return hashimoto(hash, nonce, uint64(len(dataset))*4, lookup)
}
上文可以看到hashimotoFull函数将计算的过程完全代理给了hashimoto函数,本身并没有过多的数据计算和操作,我们再深入到最深的兔子洞—hashitmoto()函数来看一下。
// 针对某个header和nonce,hashimoto函数采撷DataSet中部分数据来进行哈希
func hashimoto(hash []byte, nonce uint64, size uint64, lookup func(index uint32) []uint32) ([]byte, []byte) {
// 计算理论上用的到的“行”
rows := uint32(size / mixBytes)
// 组合header+nonce 形成 64 byte 的seed
seed := make([]byte, 40)
copy(seed, hash)
binary.LittleEndian.PutUint64(seed[32:], nonce)
seed = crypto.Keccak512(seed)
seedHead := binary.LittleEndian.Uint32(seed)
// 用seed开始“混合”操作
mix := make([]uint32, mixBytes/4)
for i := 0; i < len(mix); i++ {
mix[i] = binary.LittleEndian.Uint32(seed[i%16*4:])
}
// 混合入数据集DataSet中的数据
temp := make([]uint32, len(mix))
for i := 0; i < loopAccesses; i++ {
parent := fnv(uint32(i)^seedHead, mix[i%len(mix)]) % rows
for j := uint32(0); j < mixBytes/hashBytes; j++ {
copy(temp[j*hashWords:], lookup(2*parent+j))
}
fnvHash(mix, temp)
}
// 压缩混合
for i := 0; i < len(mix); i += 4 {
mix[i/4] = fnv(fnv(fnv(mix[i], mix[i+1]), mix[i+2]), mix[i+3])
}
mix = mix[:len(mix)/4]
digest := make([]byte, common.HashLength)
for i, val := range mix {
binary.LittleEndian.PutUint32(digest[i*4:], val)
}
// 返回混合的哈希值,输出
return digest, crypto.Keccak256(append(seed, digest...))
}
至此我们已经清晰地分析了整个试算nonce值的过程,整个过程犹如爱丽丝漫游仙境,需要层层向下探索兔子洞,按照“Seal -> mine -> hashimotoFull -> hashimoto”的顺序一层层往下解读源代码,找到试算nonce的过程,一旦找到合法的nonce立即停止多线程的mine挖矿过程,返回最终结果给Seal函数,形成合法的区块头。
Previous
© Copyright 2019, laalaguer.
Built with Sphinx using a
theme
provided by Read the Docs.
以太坊挖矿源码:ethash算法 - 一面千人 - 博客园
以太坊挖矿源码:ethash算法 - 一面千人 - 博客园
会员
周边
新闻
博问
AI培训
云市场
所有博客
当前博客
我的博客
我的园子
账号设置
简洁模式 ...
退出登录
注册
登录
一面千人
衣不鲜,体不健,学而时习,悠哉悠哉!
博客园
首页
新随笔
订阅
管理
以太坊挖矿源码:ethash算法
本文具体分析以太坊的共识算法之一:实现了POW的以太坊共识引擎ethash。
关键字:ethash,共识算法,pow,Dagger Hashimoto,ASIC,struct{},nonce,FNV hash,位运算,epoch
Ethash
前面我们分析了以太坊挖矿的源码,挖了一个共识引擎的坑,研究了DAG有向无环图的算法,这些都是本文要研究的Ethash的基础。Ethash是目前以太坊基于POW工作量证明的一个共识引擎(也叫挖矿算法)。它的前身是Dagger Hashimoto算法。
Dagger Hashimoto
作为以太坊挖矿算法Ethash的前身,Dagger Hashimoto的目的是:
抵制矿机(ASIC,专门用于挖矿的芯片)
轻客户端验证
全链数据存储
Dagger和Hashimoto其实是两个东西,
Hashimoto算法
是这个人Thaddeus Dryja创造的。旨在通过IO限制来抵制矿机。在挖矿过程中,使内存读取限制条件,由于内存设备本身会比计算设备更加便宜以及普遍,在内存升级优化方面,全世界的大公司也都投入巨大,以使内存能够适应各种用户场景,所以有了随机访问内存的概念RAM,因此,现有的内存可能会比较接近最优的评估算法。Hashimoto算法使用区块链作为源数据,满足了上面的1和3的要求。
Dagger算法
是这个人Vitalik Buterin发明的。它利用了有向无环图DAG同时实现了Memory-Hard Function内存计算困难但易于验证Memory-easy verification的特性(我们知道这是哈希算法的重要特性之一)。它的理论依据是基于每个特定场合nonce只需要大型数据总量树的一小部分,并且针对每个特定场合nonce的子树的再计算是被禁止挖矿的。因此,需要存储树但也支持一个独立场合nonce的验证价值。Dagger算法注定要替代现存的仅内存计算困难的算法,例如Scrypt(莱特币采用的),它是计算困难同时验证亦困难的算法,当他们的内存计算困难度增加至真正安全的水平,验证的困难度也随之难上加难。然而,Dagger算法被证明是容易受到Sergio Lerner发明的共享内存硬件加速技术,随后在其他路径的研究方面,该算法被遗弃了。
Memory-Hard Function
直接翻译过来是内存困难函数,这是为了地址矿机而诞生的一种思想。我们知道挖矿是靠我们的电脑,但是有些硬件厂商会制造专门用于挖矿的硬件设备,它们并不是一台完整的PC机,例如ASIC、GPU以及FPGAs(我们经常能听到GPU挖矿等)。所以这些作为矿机的设备是超越普通PC挖矿的存在,这是不符合我们区块链的去中心化精神的,所以我们要让挖矿设备平等。
那么该如何让挖矿设备是平等的呢?
上面谈到Dagger算法的时候其实提到了,这里换一种方式再来介绍一下,现在CPU都是多核的,如果从计算能力来讲,CPU有几核就可以模拟几台设备同时平行挖矿,自然效率就高些,但是这里采用的衡量对象是内存,一台电脑只有一个总内存。我们做过java多线程开发的朋友知道,无论机器性能有多高,但我们写的程序就是单线程的,那么这个程序运行在高配多核电脑和低配单核电脑的区别不大,只要他们的单核运算能力和内存大小一样即可。所以也是这个原理,通过Dagger算法,我们将挖矿流程锁定在以内存为衡量标准的硬件性能上,只要通过“塞一堆数据到内存中”的方式,让多核平行处理发挥不出来,降低硬件的运算优势,只与内存大小有关,这样无论是PC机还是ASIC、GPU以及FPGAs,都可达到平等挖矿的诉求,这也是ASIC-resistant原理,目前抵制矿机的主要手段。
两个问题的研究
在Dagger以及Dagger Hashimoto算法中,有两个问题的研究是被搁置的,
基于区块链的工作量证明:一个POW函数包括了运行区块链上的合约。该方法被抛弃是因为这是一个长期的攻击缺陷,因为攻击者能够创建分叉,然后通过一个包含秘密的快速“trapdoor”井盖门的运行机制的合约在该分叉上殖民。
随机环路:一个POW函数由这个人Vlad Zamfir开发,包含了每1000个场合nonces就生成一个新的程序的功能。本质上来讲,每次选择一个新的哈希函数,会比可重配置的FPGAs(可重编程的芯片,不必重新焊接电路板就可通过软件技术重新自定义硬件功能)更快。该方法被暂时搁置,是因为它很难看到有什么机制可以用来生成随机程序是足够全面,因此它的专业化收益是较低的。然而,我们并没有看到为什么这个概念无法让它生效的根本原因,所以暂时搁置。
Dagger Hashimoto算法
(区别于Hashimoto)Dagger Hashimoto不是直接将区块链作为数据源,而是使用一个1GB的自定义生成的数据集cache。
这个数据集是基于区块数据每N个块就会更新。该数据集是使用Dagger算法生成,允许一个自己的高效计算,特定于每个轻客户端校验算法的场合nonce。
(区别于Dagger)Dagger Hashimoto克服了Dagger的缺陷,它用于查询区块数据的数据集是半永久的,只有在偶然的间隔才会被更新(例如每周一次)。这意味着生成数据集将非常容易,所以Sergio Lerner的争议共享内存加速变得微不足道了。
挖矿补充
前面我已经写了一盘关于挖矿的文章了,这一节是挖矿的补充内容。
以太坊将过渡到POS(proof-of-stake),代替传统的POW,挖矿将会被淘汰掉,所以现在不推荐再去做一名矿工(前期购买设备等成本较大,POS实现前未必能回本)。
挖掘以太币=网络安全=验证估算
目前以太坊的POW算法是Ethash,
Ethash算法包含找到一个nonce值输入到一个算法中,得到的结果是低于一个基于特定困难度的阀值。
POW算法的关键点是除了暴力枚举,没有任何办法可以找到这个nonce值,但对于验证输出的结果是非常简单容易的。如果输出结果有一个均匀分布,我们就可以保证找到一个nonce值的平均所需时间取决于那个难度阀值,因此我们可以通过调整难度阀值来控制找到一个新块的时间,这就是控制出块速度的原理。
DAG
Ethash的POW是memory-hard,支持矿机抵御。这意味着POW计算需要选择一个固定的依赖于nonce值和块头的资源的子集。
这个资源(大约1G大小)就是DAG!
一世epoch
每3万个块会花几个小时的时间生成一个有向无环图DAG。这个DAG被称为epoch,一世(为了好记,refer个秦二世)。DAG只取决于区块高度,它可以被预生成,如果没有预生成的话,客户端需要等待预生成流程结束以后才能继续出块操作。除非客户端真实的提前预缓存了DAG,否则在每个epoch的过渡期间,网络可能会经历一个巨大的区块延迟。
特例:当你从头启动一个结点时,挖矿工作只会在创建了现世DAG以后启动。
挖矿奖励
有三部分:
静态区块创建奖励,精确发放3以太币作为奖励。
当前区块包含的所有交易的gas钱,随着时间推移,gas会越来越便宜,获得的gas总和奖励会低于静态区块创建奖励。
叔块奖励,整块奖励的1/32。
Ethash
Ethash算法路线图:
存在一个种子seed,通过扫描块头为每个块计算出来那个点。
根据这个种子seed,可以计算一个16MB的伪随机缓存cache,轻客户端存储这个缓存。
从这个缓存cache中,我们能够生成一个1GB的数据集,该数据集中的每一项都取决于缓存中的一小部分。完整客户端和矿工存储了这个数据集,数据集随着时间线性增长。
挖矿工作包含了抓取数据集的随机片以及运用哈希函数计算他们。校验工作能够在低内存的环境下完成,通过使用缓存再次生成所需的特性数据集的片段,所以你只需要存储缓存cache即可。
以上提到的大数据集是每3万个块更新一次,所以绝大多数的矿工的工作是读取该数据集而不是改变它。
pkg ethash源码分析
以上我们将所有的概念抽象梳理了一下,包括POW,挖矿,Ethash原理流程等,下面我们带着这些理论知识走进源代码中去分析具体的实现。正如我们的题目,本文主要分析的是ethash算法,因此整个源码范围仅限于go-ethereum/consensus/ethash包,该包实现了ethash pow的共识引擎。
入口
分析源码要有个入口,这个入口就是在《以太坊源码机制:挖矿》中挖下的坑“Seal方法”,原文留下了这个印子,在本文进行展开讨论。
在go-ethereum/consensus/consensus.go 接口中定义了如下的方法,正是对应上面的“Seal方法”,该接口方法的定义如下:
Seal(chain ChainReader, block *types.Block, stop <-chan struct{}) (*types.Block, error)//该方法通过输入一个包含本地矿工挖出的最高区块在主干上生成一个新块。
参数有ChainReader,Block,stop结构体信号,返回一个主链上的新出的块实体。
ChainReader
// 定义了一些方法,用于在区块头验证以及叔块验证期间,访问本地区块链。
type ChainReader interface {
// 获取区块链的链配置
Config() *params.ChainConfig
// 从本地链获取当前块头
CurrentHeader() *types.Header
// 通过hash和number从主链中获取一个区块头
GetHeader(hash common.Hash, number uint64) *types.Header
// 通过number从主链中获取一个区块头
GetHeaderByNumber(number uint64) *types.Header
// 通过hash从主链中获取一个区块头
GetHeaderByHash(hash common.Hash) *types.Header
// 通过hash和number从主链中获取一个区块
GetBlock(hash common.Hash, number uint64) *types.Block
}
总结,ChainReader定义了几个方法:从本地区块链获取配置、区块头,从主链中获取区块头、区块,参数条件包括hash和number,随意组合。
Block
// Block代表以太坊区块链中的一个完整的区块
type Block struct {
header *Header // 区块包括头
uncles []*Header // 叔块
transactions Transactions // 交易集合
// caches缓存
hash atomic.Value
size atomic.Value
// Td用于core包存储所有的链上的难度
td *big.Int
// 这些字段用于eth包来跟踪inter-peer内部端点区块的接替
ReceivedAt time.Time
ReceivedFrom interface{}
}
总结,Block除了我们熟知的区块中必有的区块头、叔块以及打包存储的交易信息,还有cache缓存的内容,以及每个块之于链的难度值,还有用于跟踪内部端点的字段。
stop
stop是一个空结构体作为信号源。
关于空结构体的讨论,为什么go里面经常出现struct{}?
go中除了struct{}类型以外,其他类型都是width,占有存储,而struct{}没有字段,没有方法,width为0,灵活性高,不占内存空间,这可能是让Gopher青睐的原因。
sealer
seal方法有两个实现,我们选择ethash,该方法存在于consensus/ethash/sealer.go文件中,第一个函数就是seal的实现,先来看该方法的声明部分:
// 尝试找到一个nonce值能够满足区块难度需求。
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, stop <-chan struct{}) (*types.Block, error) {
可以看出这个方法是属于Ethash的指针对象的,
type Ethash struct {
// cache配置
cachedir string // 缓存位置
cachesinmem int // 在内存中缓存的数量
cachesondisk int // 在硬盘中缓存的数量
// DAG挖矿数据集配置
dagdir string // DAG位置,存储全部挖矿数据集
dagsinmem int // 在内存中DAG的数量
dagsondisk int // 在硬盘中DAG的数量
// 内存cache
caches map[uint64]*cache // 内存缓存,可反复使用避免再生太频繁
fcache *cache // 为了下一世估算的预生产缓存
// 内存数据集
datasets map[uint64]*dataset // 内存数据集,可反复使用避免再生太频繁
fdataset *dataset // 为了下一世估算的预生产数据集
// 挖矿相关字段
rand *rand.Rand // 随机工具,用来为nonce做适当的种子
threads int // 如果在挖矿,代表挖矿的线程编号
update chan struct{} // 更新挖矿中参数的通道
hashrate metrics.Meter // 测量跟踪平均哈希率
// 以下字段是用于测试
tester bool // 是否使用一个小型测试数据集的标志位
shared *Ethash // 共享pow模式,无法再生缓存
fakeMode bool // Fake模式,是否取消POW检查的标志位
fakeFull bool // 是否取消所有共识规则的标志位
fakeFail uint64 // 未通过POW检查的区块号(包含fake模式)
fakeDelay time.Duration // 验证工作返回消息前的休眠延迟时间
lock sync.Mutex // 为了内存中的缓存和挖矿字段,保证线程安全
}
为了更好的读懂之后的代码,我们要对区块头的数据结构进行一个分析:
type Header struct {
ParentHash common.Hash `json:"parentHash" gencodec:"required"`
UncleHash common.Hash `json:"sha3Uncles" gencodec:"required"`
Coinbase common.Address `json:"miner" gencodec:"required"`
Root common.Hash `json:"stateRoot" gencodec:"required"`
TxHash common.Hash `json:"transactionsRoot" gencodec:"required"`
ReceiptHash common.Hash `json:"receiptsRoot" gencodec:"required"`
Bloom Bloom `json:"logsBloom" gencodec:"required"`
Difficulty *big.Int `json:"difficulty" gencodec:"required"`
Number *big.Int `json:"number" gencodec:"required"`
GasLimit *big.Int `json:"gasLimit" gencodec:"required"`
GasUsed *big.Int `json:"gasUsed" gencodec:"required"`
Time *big.Int `json:"timestamp" gencodec:"required"`
Extra []byte `json:"extraData" gencodec:"required"`
MixDigest common.Hash `json:"mixHash" gencodec:"required"`
Nonce BlockNonce `json:"nonce" gencodec:"required"`
}
可以看到一个区块头包含了父块hash值,叔块hash值,Coinbase结点账户地址,状态根,交易hash,接受者hash,日志,难度值,块编号,最低支付gas,花费的gas,时间戳,额外数据,混合hash,nonce值(8个byte)。我们要对这些区块头的成员属性了然于胸,后面的源码内容才能更好的理解。下面我们继续Seal方法,下面展示完整代码:
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, stop <-chan struct{}) (*types.Block, error) {
// fake模式立即返回0 nonce
if ethash.fakeMode {
header := block.Header()
header.Nonce, header.MixDigest = types.BlockNonce{}, common.Hash{}
return block.WithSeal(header), nil
}
// 共享pow的话,则转到它的共享对象执行Seal操作
if ethash.shared != nil {
return ethash.shared.Seal(chain, block, stop)
}
// 创建一个runner以及它指挥的多重搜索线程
abort := make(chan struct{})
found := make(chan *types.Block)
ethash.lock.Lock() // 线程上锁,保证内存的缓存(包含挖矿字段)安全
threads := ethash.threads // 挖矿的线程s
if ethash.rand == nil {// rand为空,则为ethash的字段rand赋值
// 获得种子
seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64))
if err != nil {// 执行失败,有报错
ethash.lock.Unlock() // 先解锁
return nil, err // 程序中止,直接返回空块和报错信息
}
ethash.rand = rand.New(rand.NewSource(seed.Int64())) // 执行成功,拿到合法种子seed,通过其获得rand对象,赋值。
}
ethash.lock.Unlock() // 解锁
if threads == 0 {// 挖矿线程编号为0,则通过方法返回当前物理上可用CPU编号
threads = runtime.NumCPU()
}
if threads < 0 { // 非法结果
threads = 0 // 置为0,允许在本地或远程没有额外逻辑的情况下,取消本地挖矿操作
}
var pend sync.WaitGroup // 创建一个倒计时锁对象,go语法参照 http://www.cnblogs.com/Evsward/p/goPipeline.html#sync.waitgroup
for i := 0; i < threads; i++ {
pend.Add(1)
go func(id int, nonce uint64) {// 核心代码通过闭包多线程技术来执行。
defer pend.Done()
ethash.mine(block, id, nonce, abort, found) // Seal核心工作
}(i, uint64(ethash.rand.Int63()))//闭包第二个参数表达式uint64(ethash.rand.Int63())通过上面准备好的rand函数随机数结果作为nonce实参传入方法体
}
// 直到seal操作被中止或者找到了一个nonce值,否则一直等
var result *types.Block // 定义一个区块对象result,用于接收操作结果并作为返回值返回上一层
select { // go语法参照 http://www.cnblogs.com/Evsward/p/go.html#select
case <-stop:
// 外部意外中止,停止所有挖矿线程
close(abort)
case result = <-found:
// 其中一个线程挖到正确块,中止其他所有线程
close(abort)
case <-ethash.update:
// ethash对象发生改变,停止当前所有操作,重启当前方法
close(abort)
pend.Wait()
return ethash.Seal(chain, block, stop)
}
// 等待所有矿工停止或者返回一个区块
pend.Wait()
return result, nil
}
以上Seal方法体,针对ethash的各种状态进行了校验和流程处理,以及对线程资源的控制,下面看Seal核心工作的内容(sealer.go文件只有两个函数,一个是Seal方法,另一个就是mine方法,可以看出Seal方法是对外的,而mine方法是内部方法,只能被当前ethash包域调用):mine方法
// mine函数是真正的pow矿工,用来搜索一个nonce值,nonce值开始于seed值,seed值是能最终产生正确的可匹配可验证的区块难度
func (ethash *Ethash) mine(block *types.Block, id int, seed uint64, abort chan struct{}, found chan *types.Block) {
// 从区块头中提取出一些数据,放在一个全局变量域中
var (
header = block.Header()
hash = header.HashNoNonce().Bytes()
target = new(big.Int).Div(maxUint256, header.Difficulty) // 后面有大用,这是用来验证的target
number = header.Number.Uint64()
dataset = ethash.dataset(number)
)
// 开始生成随机nonce值知道我们中止或者成功找到了一个合适的值
var (
attempts = int64(0) // 初始化一个尝试次数的变量,下面会利用该变量耍一些花枪
nonce = seed // 初始化为seed值,后面每次尝试以后会累加
)
logger := log.New("miner", id)
logger.Trace("Started ethash search for new nonces", "seed", seed)
for {
select {
case <-abort: // 中止命令
// 挖矿中止,更新状态,中止当前操作,返回空
logger.Trace("Ethash nonce search aborted", "attempts", nonce-seed)
ethash.hashrate.Mark(attempts)
return
default: // 默认执行
// 我们没必要在每一次尝试nonce值的时候更新hash率,可以在尝试了2的X次方nonce值以后再更新即可
attempts++ // 通过次数attemp来控制
if (attempts % (1 << 15)) == 0 {// 这里是定的2的15次方,位操作符请参考 http://www.cnblogs.com/Evsward/p/go.html#%E5%B8%B8%E9%87%8F
ethash.hashrate.Mark(attempts) // 满足条件了以后,要更新ethash的hash率字段的状态值
attempts = 0 // 重置尝试次数
}
// 为这个nonce值计算pow值
digest, result := hashimotoFull(dataset, hash, nonce) // 调用的hashimotoFull函数在本包的算法库中,后面会介绍。
if new(big.Int).SetBytes(result).Cmp(target) <= 0 { // 验证标准,后面介绍
// 找到正确nonce值,创建一个基于它的新的区块头
header = types.CopyHeader(header)
header.Nonce = types.EncodeNonce(nonce) // 将输入的整型值转换为一个区块nonce值
header.MixDigest = common.BytesToHash(digest) // 将字节数组转换为Hash对象【Hash是32位的根据任意输入数据的Keccak256哈希算法的返回值】
// 封装返回一个区块
select {
case found <- block.WithSeal(header):
logger.Trace("Ethash nonce found and reported", "attempts", nonce-seed, "nonce", nonce)
case <-abort:
logger.Trace("Ethash nonce found but discarded", "attempts", nonce-seed, "nonce", nonce)
}
return
}
nonce++ // 累加nonce
}
}
}
mine方法主要就是对nonce的操作,以及对区块头的重建操作,注释中我们也留了一个坑就是对于nonce尝试的工作,这部分内容会转到算法库中来介绍。
algorithm
ethash包中包含几个algorithm开头的文件,这些文件的内容是pow核心算法,用来支持挖矿操作。首先我们继续上面留的坑继续研究。
hashimotoFull函数
该函数位于ethash/algorithm.go文件中,
// 在传入的数据集中通过hash和nonce值计算加密值
func hashimotoFull(dataset []uint32, hash []byte, nonce uint64) ([]byte, []byte) {
// 本函数核心代码段:定义一个lookup函数,用于在数据集中查找数据
lookup := func(index uint32) []uint32 {
offset := index * hashWords // hashWords是上面定义的常量值= 16
return dataset[offset : offset+hashWords]
}
// hashimotoFull函数做的工作就是将原始数据集进行了读取分割,然后传给hashimoto函数。
return hashimoto(hash, nonce, uint64(len(dataset))*4, lookup)
}
hashimoto函数
继续分析,上面的hashimotoFull函数返回的是hashimoto函数的返回值,hashimoto算法我们在上面概念部分已经介绍过了,读源码的朋友不理解的可以翻回上面仔细了解一番再回到这里继续研究。
// 该函数与hashimotoFull有着相同的愿景:在传入的数据集中通过hash和nonce值计算加密值
func hashimoto(hash []byte, nonce uint64, size uint64, lookup func(index uint32) []uint32) ([]byte, []byte) {
// 计算数据集的理论的行数
rows := uint32(size / mixBytes)
// 合并header+nonce到一个40字节的seed
seed := make([]byte, 40) // 创建一个长度为40的字节数组,名字为seed
copy(seed, hash)// 将区块头的hash(上面提到了Hash对象是32字节大小)拷贝到seed中。
binary.LittleEndian.PutUint64(seed[32:], nonce) // 将nonce值填入seed的后(40-32=8)字节中去,(nonce本身就是uint64类型,是64位,对应8字节大小),正好把hash和nonce完整的填满了40字节的seed
seed = crypto.Keccak512(seed) // seed经历一遍Keccak512加密
seedHead := binary.LittleEndian.Uint32(seed) // 从seed中获取区块头,代码后面详解
// 开始与重复seed的混合
mix := make([]uint32, mixBytes/4)// mixBytes常量= 128,mix的长度为32,元素为uint32,是32位,对应为4字节大小。所以mix总共大小为4*32=128字节大小
for i := 0; i < len(mix); i++ {
mix[i] = binary.LittleEndian.Uint32(seed[i%16*4:])// 共循环32次,前16和后16位的元素值相同
}
// 做一个temp,与mix结构相同,长度相同
temp := make([]uint32, len(mix))
for i := 0; i < loopAccesses; i++ { // loopAccesses常量 = 64,循环64次
parent := fnv(uint32(i)^seedHead, mix[i%len(mix)]) % rows // mix[i%len(mix)]是循环依次调用mix的元素值,fnv函数在本代码后面详解
for j := uint32(0); j < mixBytes/hashBytes; j++ {
copy(temp[j*hashWords:], lookup(2*parent+j))// 通过用种子seed生成的mix数据进行FNV哈希操作以后的数值作为参数去查找源数据(太绕了)拷贝到temp中去。
}
fnvHash(mix, temp) // 将mix中所有元素都与temp中对应位置的元素进行FNV hash运算
}
// mix大混淆
for i := 0; i < len(mix); i += 4 {
mix[i/4] = fnv(fnv(fnv(mix[i], mix[i+1]), mix[i+2]), mix[i+3])
}
// 最后有效数据只在前8个位置,后面的数据经过上面的循环混淆以后没有价值了,所以将mix的长度减到8,保留前8位有效数据。
mix = mix[:len(mix)/4]
digest := make([]byte, common.HashLength) // common.HashLength=32,创建一个长度为32的字节数组digest
for i, val := range mix {
binary.LittleEndian.PutUint32(digest[i*4:], val)// 再把长度为8的mix分散到32位的digest中去。
}
return digest, crypto.Keccak256(append(seed, digest...))
}
该函数除了被hashimotoFull函数调用以外,还会被hashimotoLight函数调用。顾名思义,hashimotoLight是相对于hashimotoFull的存在。hashimotoLight在后面有机会就介绍(看看能不能绕进我们的route吧)。
下划线与位运算|
以上代码中的seedHead := binary.LittleEndian.Uint32(seed),我们挑出来单练,跳转到内部方法为:
func (littleEndian) Uint32(b []byte) uint32 {
_ = b[3] // bounds check hint to compiler; see golang.org/issue/14808
return uint32(b[0]) | uint32(b[1])<<8 | uint32(b[2])<<16 | uint32(b[3])<<24
}
go语法补充:下划线变量代表Go语言“垃圾桶”的意思,这个垃圾桶并不是说销毁一个对象,而是针对go语言报错机制来处理的,所以b[3]这一行可以是b[3]未使用防止go报“xxx未使用”的错误,同时观察后面的官方注释,也是为了在真正使用b[3]数据前进行边界检查,如果b[3]为空,则会提前报错,不会引发程序问题。
位运算,我们在《掌握一门语言GO》中对左移和右移进行了介绍,这里针对或|和与&进行介绍。位运算都是将原数据转换为二进制进行运算,或|就是0和1或得1,例如1和2或得3,因为1的二进制表达为01,2的二进制表达为10,01和10或运算以后就是11,等于3。同理,与&运算就是,0和1与得0,所以1和2的与运算结果为0,因为与&运算是只有都为1才能得1。
FNV hash 算法
FNV是由三位创建者的名字得来的,我们知道hash算法最重要的目标就是要平均分布(高度分散),避免碰撞,最好相近的源数据加密后完全不同,哪怕他们只有一个字母不一样,FNV hash算法就是这样的一种算法。
func fnv(a, b uint32) uint32 {
return a*0x01000193 ^ b
}
func fnvHash(mix []uint32, data []uint32) {
for i := 0; i < len(mix); i++ {
mix[i] = mix[i]*0x01000193 ^ data[i]
}
}
0x01000193是FNV hash算法的一个hash质数(Prime number,又叫素数,只能被1和其本身整除),哈希算法会基于一个常数来做散列操作。0x01000193是FNV针对32 bit数据的散列质数。
验证方式
我们一直提,pow是难于计算,上面这么长篇章深刻体现了这一点,但是pow是易于验证的,所以本节讨论的是ethash的pow的验证方式,这个验证方式也很容易找到,就是上面mine方法中我在注释里留下的坑:
new(big.Int).SetBytes(result).Cmp(target) <= 0
我们的核心计算nonce对应的加密值digest方法hashimoto算法返回了一个digest和一个result两个值,而由这行代码可知,与验证方式相关的就是result的值。result在hashimoto算法中最终还经过了crypto.Keccak256(append(seed, digest...)的Keccak256加密,参数列表中也看到了digest值。得到result值以后,就要执行上面这行代码的表达式了。这行表达式很简单,主要含义就是将result值和target值进行比较,如果小于等于0,即为通过。
那么target是什么?
target被定义在mine方法体中靠前的变量声明部分,
target = new(big.Int).Div(maxUint256, header.Difficulty)
可以看出,target的定义是根据区块头中的难度值运算而得出的。所以,这就验证了我们最早在概念部分中提到的,我们可以通过调整Difficulty值,来控制pow运算难度,生成正确nonce的难度,达到pow工作量可控的目标。
总结
代码读到这里,已经完成了一个闭环,结合前面的《挖矿》,我们已经走通了以太坊pow的全部流程,整个流程我没有丝毫懈怠,从入口深入到内核,我们把源码扒了底掉(实际上,目前为止的流程中,以太坊的pow并未真正使用到如我所想的DAG)。到目前为止,我们对pow,以及以太坊ethash的实现有了深刻的理解与认识,相信如果让我们去实现一套pow,也是完全有能力的。大家在阅读本文时有任何疑问均可留言给我,我一定会及时回复。
参考资料
go-ethereum源码,以太坊官方文档,网络名词解释文章
更多文章请转到醒者呆的博客园。
posted @
2018-03-23 18:55
一面千人
阅读(24243)
评论(11)
编辑
收藏
举报
会员力量,点亮园子希望
刷新页面返回顶部
公告
Copyright © 2024 一面千人
Powered by .NET 8.0 on Kubernetes
挖矿算法 | ethereum.org
| ethereum.org跳转至主要内容学习用法构建参与研究搜索语言 ZH帮助更新此页面本页面有新版本,但现在只有英文版。请帮助我们翻译最新版本。翻译页面没有错误!此页面未翻译,因此特意以英文显示。不再显示Change page概述基础主题以太坊简介以太币简介去中心化应用程序简介Web2 与 Web3 的对比帐户交易区块以太坊虚拟机 (EVM)操作码Gas费用节点和客户端运行节点客户端多样性节点即服务节点架构轻客户端归档节点引导节点网络共识机制工作量证明矿工挖矿算法Dagger-HashimotoEthash权益证明Gasper弱主观性认证权益证明机制的奖励和惩罚权益证明攻击与防御密钥权益证明与工作量证明提出区块权益正明常见问题以太坊堆栈堆栈简介智能合约智能合约语言智能合约结构智能合约库测试用智能合约编译智能合约部署智能合约验证智能合约升级智能合约智能合约安全性智能合约形式化验证可组合性开发网络开发框架以太坊客户端APIJavaScript API后端APIJSON-RPC数据和分析区块浏览器存储集成开发环境 (IDE)编程语言DartDelphi.NETGolangJavaJavaScriptPythonRubyRust语言高级链桥标准令牌标准ERC-20:同质化代币ERC-721:非同质化代币 (NFT)ERC-777ERC-1155ERC-4626最大可提取价值 (MEV)预言机缩放乐观卷叠零知识卷叠状态通道侧链以太坊 Plasma 扩容解决方案Validium数据可用性网络层网络地址门户网络数据结构与编码默克尔前缀树递归长度前缀编码 (RLP)简单序列化 (SSZ)Web3 密钥存储定义设计基础设计和用户体验简介挖矿算法x上次修改时间: @xiaomage(opens in a new tab), Invalid DateTime查看贡献者在本页面前提条件Dagger HashimotoEthash延伸阅读工作量证明不再是以太坊共识机制的基础,这意味着挖矿已终结。 取而代之的是,以太坊将由质押了以太币的验证者保护。 你可以立即开始质押以太币。 阅读更多关于合并、权益证明和质押的信息。 此页面仅为满足对历史的兴趣。以太坊挖矿使用过一种称为 Ethash 的算法。 该算法的基本思想是,矿工尝试使用蛮力计算找到一个随机数输入,使得生成的哈希小于一个取决于计算难度的阈值。 此难度级别可以动态调整,从而允许定期进行区块生产。前提条件为了更好地理解本页内容,推荐你先阅读工作量证明共识和挖矿。Dagger HashimotoDagger Hashimoto 是以太坊挖矿的先导研究算法,现已被 Ethash 取代。 它是两种不同算法:Dagger 和 Hashimoto 的融合。 它只是一个研究实现,并在以太坊主网启动时被 Ethash 取代。Dagger(opens in a new tab) 会生成一个有向无环图(opens in a new tab),将共同取哈希值的内容随机划分。 其核心原理是,每个随机数只取总数据树的一小部分。 挖矿禁止为每个随机数重新计算子树,因此需要总存储树,但若为验证某个随机数的价值,则可以重新计算。 Dagger 的设计目的是替代诸如 Scrypt 的已有算法。后者是“内存困难算法”,但当它们的内存困难程度增加到可信的安全水平时将很难验证。 然而,Dagger 容易受到共享内存硬件加速的影响,因此我们放弃了这种算法,转而采用了其他研究途径。Hashimoto(opens in a new tab) 算法通过实现输入/输出密集的特性(即,内存读取速度是挖矿过程中的限制因素)来增加对专用集成电路的抵抗性。 理论上来说使用内存比使用计算能力更容易;已有价值数十亿美元的经费投入被用于研究针对不同应用场景的内存优化,通常涉及近随机访问模式(即“随机存取存储器”)。 因此,现有的内存对评价算法效率的能力更接近最优。 Hashimoto 使用区块链作为数据源,同时满足上述第 (1) 和第 (3) 条。Dagger-Hashimoto 是在 Dagger 和 Hashimoto 的基础上改进而来的以太币挖矿算法。 Dagger Hashimoto 和 Hashimoto 的差别在于,Dagger Hashimoto 的数据来源并非是区块链,而是自定义生成的数据集,这些数据集将基于所有 N 区块上的区块数据进行更新。 这些数据集采用 Dagger 算法生成,可为轻量级客户端的验证算法高效计算特定于每个随机数的子集。 Dagger Hashimoto 算法和 Dagger 算法的差别在于,与原来的 Dagger 不同,用于查询区块的数据集只是暂时的,只会偶尔更新(例如每周更新一次)。 这意味着生成数据集的工作量接近于零,所以 Sergio Lerner 关于共享内存加速的论据变得微不足道。详细了解 Dagger-Hashimoto。EthashEthash 是在现已弃用的工作量证明架构下,实际用于真正的以太坊主网的挖矿算法。 Ethash 实际上是为 Dagger Hashimoto 算法进行重要更新后的一个特殊版本命名的新名称,但它仍然继承了其前身的基本原理。 以太坊主网只使用过 Ethash - Dagger Hashimoto 是挖矿算法的研发版本,在以太坊主网上开始挖矿之前被取代。详细了解 Ethash。延伸阅读还有哪些社区资源对你有所帮助? 请编辑本页面并添加!back-to-top ↑本文对你有帮助吗?是否前一页矿工下一页Dagger-Hashimoto编辑页面(opens in a new tab)在本页面前提条件Dagger HashimotoEthash延伸阅读网站最后更新: 2024年2月16日(opens in a new tab)(opens in a new tab)(opens in a new tab)使用以太坊查找钱包获取以太币Dapps - 去中心化应用二层网络运行节点稳定币质押ETH学习学习中心什么是以太坊?什么是以太币 (ETH)?以太坊钱包Gas fees以太坊安全和预防欺诈措施什么是 Web3?智能合约以太坊能源消耗以太坊路线图以太坊改进提案 (Eip)以太坊的历史以太坊白皮书以太坊词汇表以太坊治理区块链桥零知识证明测试中心开发者开始体验相关文档教程通过编码来学习设置本地环境生态系统社区中心以太坊基金会以太坊基金会的博客(opens in a new tab)生态系统支持方案(opens in a new tab)以太坊漏洞悬赏计划生态系统资助计划以太坊品牌资产Devcon(opens in a new tab)企业级应用主网以太坊私密以太坊企业级应用关于ethereum.org关于我们工作机会参与贡献语言支持隐私政策使用条款缓存政策联系我们(opens in a new t以太坊挖矿难度调整算法详解 - 知乎
以太坊挖矿难度调整算法详解 - 知乎首发于区块链技术详解切换模式写文章登录/注册以太坊挖矿难度调整算法详解Zarten计算机技术与软件专业技术资格证持证人作者:Zarten知乎专栏:区块链技术详解知乎ID:Zarten简介: 互联网一线工作者,尊重原创并欢迎评论留言指出不足之处,也希望多些关注和点赞是给作者最好的鼓励 !概述跟比特币不同,在以太坊系统中每个区块都可能进行难度调整,且在以太坊不同的发展阶段,难度的调整算法也不相同。以太坊的发展阶段以太坊的发展阶段大体分为4个阶段:1)边境(Frontier,2015年7月):以太坊网络第一次上线,开发者可以在上面挖以太币,并开始开发dApp和各种工具。2)家园(Homestead,2016年3月):以太坊发布了第一个正式版本,对协议进行了优化,为之后的升级奠定了基础,并加快了交易速度。3)大都会(Metropolis,2017年10月):这个阶段分两次上线,分别是拜占庭是拜占庭(Byzantium,2017年10月)和君士坦丁堡(Constantinople,2019年1月),让以太坊变得更轻量、更快速、更安全。4)宁静(Serenity,时间待定):这个阶段将会为我们带来期待已久的PoS共识,使用Casper共识算法。目前以太坊处在大都会中的君士坦丁堡(Constantinople)阶段,所以难度调整也是君士坦丁堡(Constantinople)阶段的算法。但是君士坦丁堡(Constantinople)阶段的算法跟拜占庭(Byzantium)的算法基本一样,只是难度炸弹回调了500万,如下所示,地址:所以接下来以拜占庭阶段(Byzantium)的算法进行讲解。难度调整算法总体的公式为:D(H) = 基础部分 + 难度炸弹第一部分图1如下:从图1分析:*注意:由于知乎特殊符号无法显示,下面将用近似符号表示D(H):是本区块的难度P(H)Hd + x * s2:是基础难度P(H)Hd为父区块的难度 x * s2 用于自适应调节出块难度e:难度炸弹最小值D0: 131072第二部分下面分析x 和 s2图2如下:从图2分析:x:父区块的难度除以2048后向下取整s2 :y的值为2或,当父区块中包含了叔父uncle区块时,y为2,否则为1Hs:是本区块的时间戳,单位秒P(H)Hs:父区块的时间戳,单位秒-99:难度降低的上界设置为−99 ,主要是应对被黑客攻击 或其他目前想不到的黑天鹅事件第三部分接下来解释难度炸弹图3如下:图3分析如下:e:每十万个块扩大一倍,是2的指数函数,到了后期 增长非常快,这就是难度“炸弹”的由来Hi':称为fake block number,由真正的block number 减少三百万得到。这样做的原因是低估了PoS协议的 开发难度。PS:目前处在君士坦丁堡(Constantinople)阶段,所以这个值是500万。算法分析从上面第一部分看到,真正决定难度的地方在于:x * s2 和 e,其他部分都是相对固定的值。基础x * s2分析从上图看到:x也为相对固定的值,难度实际取决于s2部分。y的取值为:1(无uncle)和2(有uncle)因为y=2即代表父区块中有uncle区块,而有uncle区块代表新发行的货币量要增加,为了保证货币发行量稳定,此时挖矿难度会有所增加,适当降低货币发行速度。后面部分自适应调整部分,Hs是本区块的时间戳,P(H)Hs是父区块的时间戳,当y=1举例说明:相减得到出块时间在[1,8]之间时,除以9是一个大于0小于1的数,向下取整即为0,y-0=1,表示出块时间过短,难度需要调大一个单位。相减得到出块时间在[9,17]之间时,除以9是一个大于1小于2的数,向下取整即为1,y-1=0,表示出块时间可以接受,难度保持不变。相减得到出块时间在[18,26]之间时,除以9是一个大于2小于3的数,向下取整即为2,y-2=-1,表示出块时间过长,难度需要调小一个单位。难度炸弹e分析从上图分析:难度炸弹呈指数增长,前期效果不太明显,越往后期效果越明显,威力也就越大。设置难度炸弹的目的在于,以太坊期望将来从POW转到POS,为了使矿工都从POW转到POS,越到后期挖矿难度就越大,迫使矿工们转到POS。但是计划总是赶不上变化,POS由于开发难度非常大,转到POS的时间也一再推迟,此时难度炸弹的威力已经显现出来了,所以后面也就一直在回调区块高度,比如拜占庭(Byzantium)回调300万和君士坦丁堡(Constantinople)回调500万的操作。Hi为目前真正的区块高度,区块高度减去300万后得到Hi'之所以减去300万后再来求解e是因为低估了PoS协议的开发难度,越往后面难度炸弹的值成指数增长。下图为难度炸弹的威力:后面断崖式下跌是回调后的效果难度调整的核心代码如下所示:地址点击此处 总结以太坊中的难度调整看起来好像很复杂的样子,其实真正的调整部分也就那几个部分。以太坊中的每个区块都会难度调整,依据是父区块的情况。以太坊中的难度调整会随着不同的阶段进行调整,不过算法都是大同小异的。编辑于 2020-05-16 19:01挖矿区块链技术赞同 10添加评论分享喜欢收藏申请转载文章被以下专栏收录区块链技术详解区块链技术深
如何挖掘以太坊:ETH 挖掘初学者指南 - 知乎
如何挖掘以太坊:ETH 挖掘初学者指南 - 知乎切换模式写文章登录/注册如何挖掘以太坊:ETH 挖掘初学者指南阿德里安什么是以太坊挖矿?加密货币挖掘是解决复杂数学问题的过程。矿工本质上是许多加密货币网络的基石,因为他们花费时间和计算能力来解决这些数学问题,为网络提供所谓的“工作量证明”,以验证以太 ( ETH ) 交易。以太坊与比特币 ( BTC ) 一样,目前使用工作量证明 (PoW) 共识流程,并将很快切换到权益证明 (PoS) 机制。除此之外,矿工负责通过此过程创建新的以太币代币,因为他们成功完成 PoW 任务会获得以太币奖励。PoW 依赖于散列函数的基本属性,散列函数是一种“加密”的数据,在程序上从一些任意输入派生而来。散列和标准加密之间的区别在于该过程只进行一种方式。 查找用于生成给定散列的输入的唯一有意义的方法是尝试散列所有可能的输入组合并查看哪个适合。由于初始数据的微小变化会产生完全不同的结果,这一事实使情况变得更加复杂。工作量证明首先根据“难度”参数指定所需的哈希列表。矿工必须暴力破解参数组合,包括前一个区块的哈希值,以创建满足难度条件的哈希值。这是一项能量密集型任务,可以通过提高或降低难度来轻松调节。 矿工有一定的“哈希率”,它定义了他们在一秒钟内尝试了多少组合,并且参与的矿工越多,为外部实体复制网络就越困难。通过投入实际工作,矿工可以保护网络。本文将指导您如何挖掘以太坊?以太坊交易是如何被挖掘的?以太坊挖矿如何运作?为什么要开采以太坊?挖矿将保护网络的行为变成了一项复杂但通常非常有利可图的业务,因此挖矿的主要动机是赚钱。矿工每个区块都会获得一定的奖励,以及用户支付的任何交易费用。费用通常对总收入的贡献很小,尽管 2020 年的去中心化金融热潮帮助改变了以太坊的这一等式。有人想要挖掘以太坊还有其他原因。一个利他的社区成员可能会为了保护网络做出贡献而决定亏本挖矿,因为每一个额外的哈希值都很重要。挖矿也有助于获得以太币,而无需直接投资资产。 家庭采矿的非常规用途是一种更便宜的取暖方式。采矿设备将电力转化为加密货币和热量——即使加密货币的价值低于能源成本,热量本身也可能对生活在寒冷气候中的人们有用。股权证明过渡会扼杀以太坊挖矿吗?对于任何潜在的以太坊矿工来说,一个共同的担忧是以太坊 2.0 路线图,该路线图引入了向权益证明过渡的计划,这是一种共识算法,在所有现有的以太坊矿工都可以在有限的时间内获得投资回报的情况下,该共识算法将弃用矿工。但值得庆幸的是,PoW 挖矿可能会在 2023 年左右之前仍然有效。 预计于 2020 年推出的 Ethereum 2.0 Phase 0 是一个独立的区块链,不会以任何方式影响采矿。只有在第 2 阶段才可能开始弃用采矿,但截至 2020 年 10 月,还没有具体的过渡计划。第二阶段预计将在2021 年底或 2022 年初左右到来。但值得指出的是,以太坊的路线图有很长的延迟历史——在 2017-2018 年,人们普遍认为过渡将在 2020 年左右完成。没有人真正知道以太坊 2.0 何时完成,但截至 2020 年 10 月,大多数估计表明,新矿工应该有足够的时间来收回至少相当一部分硬件投资。ETH 挖矿盈利能力:以太坊挖矿盈利吗?任何类型的采矿是否有利可图完全取决于任何给定区域的电力成本。作为一项规则,一小时消耗每千瓦低于 0.12 美元的任何东西都可能是有利可图的,尽管建议低于 0.06 美元的价格使采矿成为真正可行的经济企业。这些数字将取消大多数家庭采矿尝试的资格,尤其是在电价普遍高于 0.20 美元的发达国家。尽管有可能以这样的价格获利,但资本回报率可能会受到严重影响。例如,成本为 3,000 美元的矿工每月产生 200 美元的收入,而以 0.05 美元/千瓦时的价格使用 45 美元的电费将需要 19 个月才能偿还。在电力成本为 0.20 美元/千瓦时的地区使用的同一台矿机将在 150 个月或 12 年内偿还。专业矿工可以通过将其业务转移到电力最便宜的地区或利用为工业保留的普遍较低的电价来获得优势。这些是采矿业变成一个严肃的资本密集型行业的一些主要原因。但是大多数人仍然可以在家中挖掘以太坊,特别是因为它可以使用 AMD 和 Nvidia 制造的消费级显卡来完成。对于生活在低电价地区的以太坊矿工来说,它也可以成为一个强大的收入来源。 有多种 ETH 挖矿计算器可以概述预期的利润,例如http://Miningbenchmark.net、Whattomine或 CryptoCompare 的计算器。也可以独立计算这些值。计算器网站使用的公式非常简单:这提供了对矿工一天内预期收入的估计。本质上,矿工的收入是网络的总发行量乘以他们在网络总哈希率中的份额。为了盈利,需要减去矿工使用的电力成本(即以太坊挖矿的成本)。例如,以 0.10 美元的价格使用 1.5 千瓦时电力的设备每天将花费 3.6 美元。插入收入公式的值也可以在网上找到。Etherscan将提供总哈希率的更新估计,以及区块时间和区块奖励。 在以太坊网络上,当前的出块时间为 15 秒,因此一天有 5,760 个区块,截至 2020 年 10 月,每个区块的奖励为 2 ETH。矿工的哈希率完全取决于挖矿硬件,而网络哈希率是为网络做出贡献的所有矿工的总和。成功挖矿的关键是最大化哈希率,同时最小化电力和硬件成本。因此,除了位置之外,挖矿硬件的选择对于挖矿来说也是至关重要的。以太坊交易是如何被挖掘的?以太币被设计成一种只能用消费级图形处理单元或 GPU 开采的硬币。这与比特币形成鲜明对比,比特币只能通过通常称为专用集成电路机器或 ASIC 的专用设备进行有效挖掘。这些设备被固定为只执行一项任务,这使它们能够实现比更通用的计算硬件更高的效率。制作“抗 ASIC”的挖掘算法在理论上是不可能的,在实践中也非常困难。为以太坊的挖矿算法 Ethash 设计的 ASIC 最终于 2018 年发布。然而,这些矿工在哈希效率方面相对 GPU 的改进相对适度。相比之下,由于其挖掘算法的特殊性,比特币的 ASIC 比 GPU 效率高得多。另一种专用设备是 FPGA,它代表现场可编程门阵列。这些是 ASIC 和 GPU 之间的中间地带,允许某种形式的可配置性,同时在特定类型的计算中仍然比 GPU 更高效。使用所有这些设备开采以太坊是可行的,但并非所有设备都是实用或明智的。例如,在大多数情况下,FPGA 不如 GPU。它们是昂贵且非常复杂的设备,需要先进的技术知识才能有效使用。这种奖励可以说是不值得的,因为它们的挖矿性能仍然非常接近领先的 GPU。与显卡相比,以太 ASIC 提供了可衡量的性能提升,但在实际使用中存在许多缺点。最重要的问题是 ASIC 只能基于相同的哈希算法挖掘以太坊和其他一些硬币。 GPU 可以挖掘许多其他代币,并且在紧急情况下可以转售给游戏玩家或用于构建游戏 PC。此外,ASIC 更难采购,因为很少有商店出售它们,而直接从制造商处购买可能需要大量订单和漫长的等待时间。因此,对于业余爱好者家庭矿工来说,GPU 仍然是最明智的选择,因为其灵活性和与价格相比相对较好的性能。如何找到最好的挖矿硬件?选择正确的硬件主要取决于三个因素:最大可能的哈希率、能耗和购买价格。 购买价格有时会被忽略,但它可以成就或破坏挖矿业务,因为硬件不会永远持续下去。组件磨损是一个因素,因为最终,所有设备都会出现故障。然而,这个问题往往被夸大了,因为 GPU 是非常有弹性的设备,许多报告称它们持续挖掘超过五年。影响矿工的最大风险是硬件过时。更先进的 GPU 或 ASIC 几乎可以完全淘汰现有的矿工,尤其是那些电费较高的矿工。因此,“投资回收期”——矿工需要多长时间才能收回成本——成为采矿财务分析的一个非常重要的指标。下表列出了领先的以太坊挖矿硬件的财务参数: 您可以查看和复制电子表格以使用这些值。该表分析了投资回收期,其中值越低,结果越好。之所以选择此措施,是因为设备之间的哈希率差异很大,这会扭曲每日利润比较。计算完全忽略了任何产生的费用,这比块奖励更不可预测。根据日期,费用在 2020 年夏季占每日总收入的10%–50% ,但从历史上看,它们徘徊在 10% 以下。 进一步的警告是,该表是在高级牛市中编制的。一些配置已经无法赚钱,以太坊价格的任何下降都可能使情况更加恶化。总体而言,矿工收入波动很大,将一天的收益外推到未来可能非常不可靠。矿工相互竞争整体奖励,因此将运营成本降低至低于全球平均水平是弹性业务的关键。最后,该表忽略了组装矿机所需的剩余硬件成本。它主要是固定成本且相对便宜,因为 GPU 采矿设备使用 6 到 14 个 GPU。ASIC 在很大程度上是自给自足的,但通常需要购买外部电源单元。考虑到这些免责声明,比较仍然突出了各种采矿硬件选项的一些差异和缺点。例如,使用三年的 AMD RX 580 是最物有所值的,每千瓦时 0.05 美元。但它的低能源效率使其成为比其他电力成本更高的选择要弱得多的选择。对于电力成本高的矿工来说,A10 Pro ASIC 是迄今为止最节能、最具吸引力的选择。由于购买难度极大或剩余寿命短,其他 ASIC 未包括在内。Nvidia RTX 3080 也是基于初步基准测试的各类矿工 的全方位强大替代品。SQRL FK 33 是较受欢迎的 FPGA 之一,但该模型突出了为什么这种类型的硬件很少使用。尽管它的能源效率很高,但与所有其他选项相比,它的单价仍然没有吸引力。然而,值得注意的是,样本价格数据来自 eBay 的翻新二手设备列表。购买使用过的折旧 GPU,如 AMD RX Vega 64 或 Nvidia GTX 1060 也是一种很好的节省成本的措施,但购买者可能会遇到更高的设备故障风险。以太坊挖矿如何运作:指南和风险采矿需要仔细计划和注意以避免不幸的结果。所有计算机都有潜在的火灾隐患,由于持续使用和高能量输出,这种风险在采矿中被放大。对于家庭采矿环境,重要的是不要因过度用电而使国内电网过载。整个电网和每个单插座的额定功率仅为一定的最大功率,而挖矿设备很容易超过这些阈值。接线可能会出现故障和过热,从而构成直接的火灾危险。请咨询专家以评估您的设置的安全性。强烈建议选择具有足够额定功率裕度的高质量电源装置,以防止出现电涌和其他电气问题。对于 GPU 和 FPGA 采矿设备,有效挖掘以太坊有几个关键的硬件要求。投资专门的主板,例如 Asrock X370 Pro BTC+ 或 Gigabyte GA-B250-FinTech,可能非常值得,因为它们针对采矿进行了优化。每个主板最多可支持 14 个 GPU,这在标准主板上通常是不可能的。主板应配备足够数量的 RAM、8 或 16 GB 以及至少 256 GB 的驱动器存储空间。后一部分非常重要,因为以太坊挖矿需要大量运行时内存,每个 GPU 至少 4GB。通过称为页面文件缓存的操作系统技巧,可以将此要求卸载到更便宜的永久存储上,而不会造成性能损失。GPU 自身的 RAM 也必须至少为 6GB,以适应不断增长的 DAG,这是 Ethash 算法的关键机制。DAG 代表有向无环图,是一个大型数据集,用于计算用于挖掘以太坊的哈希值。挖矿硬件必须有足够的内存容量来存储它。以太币的数据集每两年以大约 1GB 的速度增长,尽管其他硬币可能有不同的增长率。到 2020 年底,4 GB 的设备将完全无法使用,而到 2024 年,6 GB 卡可能已经贬值。在线计算器可以帮助评估确切的时间表。中央处理器可以尽可能便宜,因为它与 GPU 挖掘无关。多 GPU 设置可能需要提升板,即允许将 GPU 连接到主板的适配器。矿机箱应打开且足够宽以允许空气流通。在操作系统方面,Windows 和 Linux 都是有效的选择,尽管 Linux 可能需要更多的命令行交互来设置。在时钟速度、功耗和内存时序方面优化 GPU 以实现前面概述的数据至关重要,但完整的综述超出了本指南的范围。开采 ETH 最直接的方法是加入众多以太坊矿池之一,如 SparkPool、Nanopool、F2Pool 等。这些允许矿工拥有稳定的收入流,而不是偶尔找到整个区块的随机机会。流行的挖矿软件包括 Ethminer、Claymore 和 Phoenix。可能值得对每一个进行测试,看看哪个更适合您的特定配置。最后,设备应定期维护、清洁和除尘,以保持硬件的良好状态。建立一个成功的矿场还涉及其他细节,其中许多作为商业机密被严格保密。本指南并不完全全面,但如果您认真对待采矿,您现在应该拥有强大的知识库来进行进一步的研究。发布于 2022-07-08 22:36机器学习比特币 (Bitcoin)以太坊矿池赞同添加评论分享喜欢收藏申请
挖矿 | ethereum.org
ethereum.org跳转至主要内容学习用法构建参与研究搜索语言 ZH帮助更新此页面本页面有新版本,但现在只有英文版。请帮助我们翻译最新版本。翻译页面没有错误!此页面未翻译,因此特意以英文显示。不再显示Change page概述基础主题以太坊简介以太币简介去中心化应用程序简介Web2 与 Web3 的对比帐户交易区块以太坊虚拟机 (EVM)操作码Gas费用节点和客户端运行节点客户端多样性节点即服务节点架构轻客户端归档节点引导节点网络共识机制工作量证明矿工挖矿算法Dagger-HashimotoEthash权益证明Gasper弱主观性认证权益证明机制的奖励和惩罚权益证明攻击与防御密钥权益证明与工作量证明提出区块权益正明常见问题以太坊堆栈堆栈简介智能合约智能合约语言智能合约结构智能合约库测试用智能合约编译智能合约部署智能合约验证智能合约升级智能合约智能合约安全性智能合约形式化验证可组合性开发网络开发框架以太坊客户端APIJavaScript API后端APIJSON-RPC数据和分析区块浏览器存储集成开发环境 (IDE)编程语言DartDelphi.NETGolangJavaJavaScriptPythonRubyRust语言高级链桥标准令牌标准ERC-20:同质化代币ERC-721:非同质化代币 (NFT)ERC-777ERC-1155ERC-4626最大可提取价值 (MEV)预言机缩放乐观卷叠零知识卷叠状态通道侧链以太坊 Plasma 扩容解决方案Validium数据可用性网络层网络地址门户网络数据结构与编码默克尔前缀树递归长度前缀编码 (RLP)简单序列化 (SSZ)Web3 密钥存储定义设计基础设计和用户体验简介挖矿x上次修改时间: @xiaomage(opens in a new tab), Invalid DateTime查看贡献者在本页面前提条件以太坊挖矿是什么?为什么存在矿工?挖矿成本如何挖掘以太坊交易叔块直观演示挖矿算法相关主题工作量证明不再是以太坊共识机制的基础,这意味着挖矿已终结。 取而代之的是,以太坊将由质押了以太币的验证者保护。 你可以立即开始质押以太币。 阅读更多关于合并、权益证明和质押的信息。 此页面仅展示历史内容。前提条件为了更好地了解此页面,推荐先阅读交易、区块和工作量证明。以太坊挖矿是什么?挖矿是指创建要添加到以太坊区块链的交易块的过程,在以太坊现已弃用的工作量证明架构中进行。挖矿一词源于将加密货币比作黄金的比喻。 黄金或贵金属很稀缺,数字代币也很稀缺,在工作量证明体系中,只能通过挖矿增加总量。 在工作量证明以太坊中,只能通过挖矿进行发行。 然而,与黄金或贵金属不同,以太坊挖矿也是一种通过在区块链中创建、验证、发布和传播区块来保护网络的方式。以太币挖矿 = 保护网络安全挖矿是任何工作量证明区块链的命脉。 在过渡到权益证明之前,以太坊矿工,即运行软件的计算机,利用它的时间和算力处理交易并产生区块。为什么存在矿工?在以太坊这样的去中心化系统中,需要确保每个人都同意交易的顺序。 矿工通过解决计算难题来产生区块并保护网络免受攻击,从而帮助实现这一目标。关于工作量证明的更多信息以前任何人都能使用他们的计算机在以太坊网络上挖矿。 然而,并非每个人都可以通过挖矿实现以太币 (ETH) 获利。 在大多数情况下,矿工必须购买专用计算机硬件,并且能够获得廉价能源。 普通计算机不太可能获得足够的区块奖励来支付相关的挖矿成本。挖矿成本建造和维护矿机所需硬件的潜在成本矿机的电力成本如果你在矿池中挖矿,这些矿池通常对矿池生成的每个区块收取固定百分比的费用支持矿机的潜在成本(通风、能源监测、电线等)要进一步探索挖矿收益,请使用挖矿收益计算器,例如 Etherscan(opens in a new tab) 提供的挖矿收益计算器。如何挖掘以太坊交易以下内容将简要介绍如何在以太坊工作量证明中挖掘交易。 在这里可以找到对以太坊权益证明中该过程的类比介绍。用户编写和通过一些帐户私钥来签署交易请求。用户通过一些节点将自己的交易请求广播到整个以太坊网络。在听到新的转账请求时,每个以太坊网络节点会添加这笔交易到本地的内存池,这些内存池包括他们收到的没有被添加到区块链以承认的所有转账请求。在这个时候,一个挖矿节点将几十或上百个交易请求汇总到潜在区块中,从而尽量多收取交易手续费,同时保证不超出区块燃料限制。 采矿节点将:验证每个交易请求的有效性(例如没有人试图将以太币从他们没有签名的帐户中转移出来,请求是否有格式错误等),然后执行请求的本地代码,改变本地副本 EVM 的状态。 矿工获得每个交易请求的转账的手续费到他们的帐户。一旦在本地 EVM 副本上验证并执行了块中的所有转账请求,就开始为潜在块生成工作证明“合法性证书”。最终,矿工将完成为包含我们特定交易请求的区块生成的证书。 然后,矿工广播完成的区块,其中包括证书和校验新 EVM 状态。其他节点将收到新的区块。 他们将验证证书,执行区块上所有的转账(包括最初由用户广播的交易),然后校验新 EVM 状态,之后执行所有满足 EVM 校验和的转账。 只有这样,这些节点才会将该块附加到区块链的尾部,并接受新的 EVM 状态作为新的规范状态。每个节点将从其未完成的本地内存池的转账请求中删除新区块中已经存在的转账请求。加入网络的新节点将按顺序下载所有块,包括未被打包的交易块。 初始化本地 EVM 副本(作为空白状态的 EVM 开始),在本地 EVM 副本上执行每个块中的每个转账,校验各块的校验和。每个交易都只会被挖掘(首次包含在新区块中并传播)一次,但在推进规范以太坊虚拟机状态的过程中,每个参与者都会执行和验证交易。 这凸显出区块链的核心准则之一:不信任,就验证。叔块基于工作量证明的区块挖掘是概率性的,这意味着有时由于网络延迟而同时公布了两个有效的区块。 在这种情况下,协议必须确定最长链(因此大多数即是最“有效的”),同时针对已提交但未被包含的有效区块,给予矿工部分奖励以确保公平。 这促使网络进一步去中心化,因为小矿工群体可能面临更大的延迟,但仍然可以通过叔块奖励获得收益。对于父区块的同级区块来说,“ommer”一词不分性别,因而为首选,但有时也被称为“uncle”(叔)。 因为以太坊切换到权益证明机制后,叔块就不会被挖掘了,因为每个时隙中只选择了一名提议者。 通过查看被挖掘叔块的历史图表(opens in a new tab),你可以看到这种变化。直观演示跟随 Austin 了解挖矿和工作量证明区块链。挖矿算法以太坊主网只使用过一种挖矿算法 -“Ethash”。 Ethhash 是一种初始研发挖矿算法“Dagger-Hashimoto”的后续版本。有关挖矿算法的更多信息。相关主题燃料以太坊虚拟机工作量证明back-to-top ↑本文对你有帮助吗?是否前一页工作量证明下一页挖矿算法编辑页面(opens in a new tab)在本页面前提条件以太坊挖矿是什么?为什么存在矿工?挖矿成本如何挖掘以太坊交易叔块直观演示挖矿算法相关主题网站最后更新: 2024年2月16日(opens in a new tab)(opens in a new tab)(opens in a new tab)使用以太坊查找钱包获取以太币Dapps - 去中心化应用二层网络运行节点稳定币质押ETH学习学习中心什么是以太坊?什么是以太币 (ETH)?以太坊钱包Gas fees以太坊安全和预防欺诈措施什么是 Web3?智能合约以太坊能源消耗以太坊路线图以太坊改进提案 (Eip)以太坊的历史以太坊白皮书以太坊词汇表以太坊治理区块链桥零知识证明测试中心开发者开始体验相关文档教程通过编码来学习设置本地环境生态系统社区中心以太坊基金会以太坊基金会的博客(opens in a new tab)生态系统支持方案(opens in a new tab)以太坊漏洞悬赏计划生态系统资助计划以太坊品牌资产Devcon(opens in a new tab)企业级应用主网以太坊私密以太坊企业级应用关于ethereum.org关于我们工作机会参与贡献语言支持隐私政策使用条款缓存政策联系我们(opens in a new t以太坊挖矿逻辑流程 :: 以太坊技术与实现
矿逻辑流程 :: 以太坊技术与实现以太坊技术与实现前言开始以太坊术语第一章. 基础数据结构配置创世块账户交易区块交易回执Gas第二章. 挖矿核心交易池架构设计交易存储交易入队列内存限制挖矿架构启动挖矿挖矿信号挖矿流程叔块挖矿奖励区块存储共识算法代码结构Ethash基础Ethash算法实现第三章. 底层核心技术签名与校验MPTStateDBRLPEVM第四章. 功能集第五章. 区块同步第六章. 漏洞分析TheDao第七章. Dapp开发存储布局More Github 源码 深入浅出区块链 文章标签Star Fork作者:虞双齐| 主题:learn 我要编辑 > 挖矿核心 > 以太坊挖矿逻辑 > 以太坊挖矿逻辑流程挖矿代码方法介绍挖矿工作管理新工作启动信号新交易信号挖矿流程环节设置新区块基本信息准备上下文环境选择叔块提交交易提交区块PoW计算寻找Nonce等待挖矿结果 Nonce存储与广播挖出的新块总结以太坊挖矿逻辑流程上一篇文章中,有介绍是如何发出挖矿工作信号的。当有了挖矿信号后,就可以开始挖矿了。先回头看看,在讲解挖矿的第一篇文章中,有讲到挖矿流程。这篇文章将讲解挖矿中的各个环节。挖矿代码方法介绍在继续了解挖矿过程之前,先了解几个miner方法的作用。commitTransactions:提交交易到当前挖矿的上下文环境(environment)中。上下文环境中记录了当前挖矿工作信息,如当前挖矿高度、已提交的交易、当前State等信息。updateSnapshot:更新 environment 快照。快照中记录了区块内容和区块StateDB信息。相对于把当前 environment 备份到内存中。这个备份对挖矿没什么用途,只是方便外部查看 PendingBlock。commitNewWork:重新开始下一个区块的挖矿的第一个环节“构建新区块”。这个是整个挖矿业务处理的一个核心,值得关注。commit: 提交新区块工作,发送 PoW 计算信号。这将触发竞争激烈的 PoW 寻找Nonce过程。挖矿工作管理什么时候可以进行挖矿?如下图所述,挖矿启动工作时由 mainLoop 中根据三个信号来管理。首先是新工作启动信号(newWorkCh)、再是根据新交易信号(txsCh)和最长链链切换信号(chainSideCh)来管理挖矿。三种信号,三种管理方式。新工作启动信号这个信号,意思非常明确。一旦收到信号,立即开始挖矿。//miner/worker.go:409case req := <-w.newWorkCh:
w.commitNewWork(req.interrupt, req.noempty, req.timestamp)这个信号的来源,已经在上一篇文章 挖矿工作信号监控中讲解。信号中的各项信息也来源与外部,这里仅仅是忠实地传递意图。新交易信号在交易池文章中有讲到,交易池在将交易推入交易池后,将向事件订阅者发送 NewTxsEvent。在 miner 中也订阅了此事件。worker.txsSub = eth.TxPool().SubscribeNewTxsEvent(worker.txsCh)当接收到新交易信号时,将根据挖矿状态区别对待。当尚未挖矿(!w.isRunning()),但可以挖矿w.current != nil时❶,将会把交易提交到待处理中。//miner/worker.go:451
case ev := <-w.txsCh:
if !w.isRunning() && w.current != nil {//❶
w.mu.RLock()
coinbase := w.coinbase
w.mu.RUnlock()
txs := make(map[common.Address]types.Transactions)
for _, tx := range ev.Txs {//❷
acc, _ := types.Sender(w.current.signer, tx)
txs[acc] = append(txs[acc], tx)
}
txset := types.NewTransactionsByPriceAndNonce(w.current.signer, txs)//❸
w.commitTransactions(txset, coinbase, nil)//❹
w.updateSnapshot()//❺
} else {
if w.config.Clique != nil && w.config.Clique.Period == 0 {//❻
w.commitNewWork(nil, false, time.Now().Unix())
}
}
atomic.AddInt32(&w.newTxs, int32(len(ev.Txs)))//❼首先,将新交易按发送者分组❷后,根据交易价格和Nonce值排序❸。形成一个有序的交易集后,依次提交每笔交易❹。最新完毕后将最新的执行结果进行快照备份❺。当正处于 PoA挖矿,右允许无间隔出块时❻,则将放弃当前工作,重新开始挖矿。最后,不管何种情况都对新交易数计加❼。但实际并未使用到数据量,仅仅是充当是否有进行中交易的一个标记。总得来说,新交易信息并不会干扰挖矿。而仅仅是继续使用当前的挖矿上下文,提交交易。也不用考虑交易是否已处理, 因为当交易重复时,第二次提交将会失败。###最长链链切换信号当一个区块落地成功后,有可能是在另一个分支上。当此分支的挖矿难度大于当前分支时,将发生最长链切换。此时 miner 将需要订阅从信号,以便更新叔块信息。//miner/worker.go:412
case ev := <-w.chainSideCh:
if _, exist := w.localUncles[ev.Block.Hash()]; exist {//❶
continue
}
if _, exist := w.remoteUncles[ev.Block.Hash()]; exist {
continue
}
if w.isLocalBlock != nil && w.isLocalBlock(ev.Block) {//❷
w.localUncles[ev.Block.Hash()] = ev.Block
} else {
w.remoteUncles[ev.Block.Hash()] = ev.Block
}
if w.isRunning() && w.current != nil && w.current.uncles.Cardinality() < 2 {//❸
start := time.Now()
if err := w.commitUncle(w.current, ev.Block.Header()); err == nil {//❹
var uncles []*types.Header
w.current.uncles.Each(func(item interface{}) bool {
//...
})
w.commit(uncles, nil, true, start)//❺
}
}短时间内,分支切换可能是频繁的。挖矿一直再相互竞争。如果接受到的区块,已经在叔块集中则忽略❶,没有则记录到叔块中❷。因为区块奖励是包含叔块奖励的,因此如果还在挖矿中,而叔块数量不到2个时❸。可以不再处理交易,一旦此区块加入叔块集成功❹,则直接结束交易处理,立刻将当前已处理的交易组装成区块,生成此区块的 PoW 计算信号❺。挖矿流程环节当开始新区块挖矿时,第一步就是构建区块,打包出包含交易的区块。在打包区块中,是按逻辑顺序依次组装各项信息。如果你对区块内容不清楚,请先查阅文章区块结构。设置新区块基本信息挖矿是在竞争挖下一个区块,需要把最新高度的区块作为父块来确定新区块的基本信息❶。//miner/worker.go:829
parent := w.chain.CurrentBlock()//❶
if parent.Time() >= uint64(timestamp) {//❷
timestamp = int64(parent.Time() + 1)
}
if now := time.Now().Unix(); timestamp > now+1 {
wait := time.Duration(timestamp-now) * time.Second
log.Info("Mining too far in the future", "wait", common.PrettyDuration(wait))
time.Sleep(wait)//❸
}
num := parent.Number()
header := &types.Header{//❹
ParentHash: parent.Hash(),
Number: num.Add(num, common.Big1),
GasLimit: core.CalcGasLimit(parent, w.gasFloor, w.gasCeil),
Extra: w.extra,
Time: uint64(timestamp),
}
if w.isRunning() {
if w.coinbase == (common.Address{}) {
log.Error("Refusing to mine without etherbase")
return
}
header.Coinbase = w.coinbase//❺
}先根据父块时间戳调整新区块的时间戳。如果新区块时间戳还小于父块时间戳,则直接在父块时间戳上加一秒。一种情是,新区块链时间戳比当前节点时间还快时,则需要稍做休眠❸,避免新出块属于未来。这也是区块时间戳可以作为区块链时间服务的一种保证。有了父块,新块的基本信息是确认的。分别是父块哈希、新块高度、燃料上限、挖矿自定义数据、区块时间戳❹。为了接受区块奖励,还需要设置一个不为空的矿工账户 Coinbase ❺。一个区块的挖矿难度是根据父块动态调整的,因此在正式处理交易前,需要根据共识算法设置新区块的挖矿难度❻。if err := w.engine.Prepare(w.chain, header); err != nil {//❻
log.Error("Failed to prepare header for mining", "err", err)
return
}至此,区块头信息准备就绪。准备上下文环境为了方便的共享当前新区块的信息,是专门定义了一个 environment ,专用于记录和当前挖矿工作相关内容。为即将开始的挖矿,先创建一份新的上下文环境信息。 err := w.makeCurrent(parent, header)
if err != nil {
log.Error("Failed to create mining context", "err", err)
return
}上下文环境信息中,记录着此新区块信息,分别有:state: 状态DB,这个状态DB继承自父块。每笔交易的处理,实际上是在改变这个状态DB。ancestors: 祖先区块集,用于检测叔块是否合法。family: 近亲区块集,用于检测叔块是否合法。uncles:已合法加入的叔块集。tcount: 当请挖矿周期内已提交的交易数。gasPool: 新区块可用燃料池。header: 新区块区块头。txs: 已提交的交易集合。receipts: 已提交交易产生的交易回执集合。makeCurrent方法就是在初始化好上述信息。Cd3ecj6#QG4Q3hzEU选择叔块前面不断将非分支上的区块存放在叔块集中。在打包新块选择叔块时,将从叔块集中选择适合的叔块。//miner/worker.go:886
uncles := make([]*types.Header, 0, 2)
commitUncles := func(blocks map[common.Hash]*types.Block) {
for hash, uncle := range blocks {//❷
if uncle.NumberU64()+staleThreshold <= header.Number.Uint64() {
delete(blocks, hash)
}
}
for hash, uncle := range blocks {
if len(uncles) == 2 {//❸
break
}
if err := w.commitUncle(env, uncle.Header()); err != nil {
} else {
uncles = append(uncles, uncle.Header())
}
}
}
commitUncles(w.localUncles)//❶
commitUncles(w.remoteUncles)叔块集分本地矿工打包区块和其他挖矿打包的区块。优先选择自己挖出的区块❶。选择时,将先删除太旧的区块,只从最近的7(staleThreshold)个高度中选择❷,但最多选择两个叔块放入新区块中❸。为什么不多选几个呢?这个不太清楚如何确定的。共识校验中叔块上限是2。怎样的叔块才能够被选择呢?在 commitUncle 时将根据当前新区块的高度、父区块信息来决定是否加入。//miner/worker.go:645
func (w *worker) commitUncle(env *environment, uncle *types.Header) error {
hash := uncle.Hash()
//...
if env.header.ParentHash == uncle.ParentHash {//❹
return errors.New("uncle is sibling")
}
//...
env.uncles.Add(uncle.Hash())
return nil
}唯一需要确认的是叔块必须在另一个分支上❹。总得来说,叔块是最近7个高度内上的区块,,且和当前新区块不在同一分支上、且不能重复包含在祖先块中。提交交易区块头已准备就绪,此刻开始从交易池拉取待处理的交易。将交易根据交易发送者分为两类,本地账户交易 localTxs 和外部账户交易 remoteTxs。本地交易优先不仅在交易池交易排队如此,在交易打包到区块中也是如此。本地交易优先,先将本地交易提交❸,再将外部交易提交❹。//miner/worker.go:917
pending, err := w.eth.TxPool().Pending()//❶
//...
localTxs, remoteTxs := make(map[common.Address]types.Transactions), pending//❷
for _, account := range w.eth.TxPool().Locals() {
if txs := remoteTxs[account]; len(txs) > 0 {
delete(remoteTxs, account)
localTxs[account] = txs
}
}
if len(localTxs) > 0 {//❸
txs := types.NewTransactionsByPriceAndNonce(w.current.signer, localTxs)
if w.commitTransactions(txs, w.coinbase, interrupt) {
return
}
}
if len(remoteTxs) > 0 {//❹
txs := types.NewTransactionsByPriceAndNonce(w.current.signer, remoteTxs)
if w.commitTransactions(txs, w.coinbase, interrupt) {
return
}
}交易处理完毕后,便可进入下一个环节。提交区块在交易处理完毕时,会获得交易回执和变更了区块状态。这些信息已经实时记录在上下文环境 environment 中。将 environment 中的数据整理,便可根据共识规则构建一个区块。//miner/worker.go:959
s := w.current.state.Copy()
block, err := w.engine.Finalize(w.chain, w.current.header, s, w.current.txs, uncles, w.current.receipts)有了区块,就剩下最重要也是最核心的一步,执行 PoW 运算寻找 Nonce。这里并不是立刻开始寻找,而是发送一个PoW计算任务信号。//miner/worker.go:968
select {
case w.taskCh <- &task{receipts: receipts, state: s, block: block, createdAt: time.Now()}:
//...
}PoW计算寻找Nonce之所以称之为挖矿,也是因为寻找Nonce的精髓所在。这是一道数学题,只能暴力破解,不断尝试不同的数字。直到找出一个符合要求的数字,这个数字称之为Nonce。寻找Nonce的过程,称之为挖矿。寻找Nonce是需要时间的,耗时主要由区块难度决定。在代码设计上,以太坊是在 taskLoop 方法中,一直等待 task ❶。//miner/worker.go:508
case task := <-w.taskCh://❶
//...
sealHash := w.engine.SealHash(task.block.Header())//❷
if sealHash == prev {
continue
}
interrupt()//❹
stopCh, prev = make(chan struct{}), sealHash
if w.skipSealHook != nil && w.skipSealHook(task) {
continue
}
w.pendingMu.Lock()
w.pendingTasks[w.engine.SealHash(task.block.Header())] = task//❸
w.pendingMu.Unlock()
if err := w.engine.Seal(w.chain, task.block, w.resultCh, stopCh); err != nil {
log.Warn("Block sealing failed", "err", err)
}当接收到挖矿任务后,先计算出这个区块所对应的一个哈希摘要❷,并登记此哈希对应的挖矿任务❸。登记的用途是方便查找该区块对应的挖矿任务信息,同时在开始新一轮挖矿时,会取消旧的挖矿工作,并从pendingTasks 中删除标记。以便快速作废挖矿任务。随后,在共识规则下开始寻找Nonce,一旦找到Nonce,则发送给 resutlCh。同时,如果想取消挖矿任务,只需要关闭 stopCh。而在每次开始挖矿寻找Nonce前,便会关闭 stopCh 将当前进行中的挖矿任务终止❹。//miner/worker.go:500
interrupt := func() {
if stopCh != nil {
close(stopCh)
stopCh = nil
}
}等待挖矿结果 Nonce上一步已经开始挖矿,寻找Nonce。下一步便是等待挖矿结束,在 resultLoop 中,一直在等待执行结果❶。//miner/worker.go:542
select {
case block := <-w.resultCh: //❶
if block == nil {
continue
}
if w.chain.HasBlock(block.Hash(), block.NumberU64()) {//❷
continue
}
var (
sealhash = w.engine.SealHash(block.Header())
hash = block.Hash()
)一旦找到Nonce,则说明挖出了新区块。存储与广播挖出的新块挖矿结果已经是一个包含正确Nonce 的新区块。在正式存储新区块前,需要检查区块是否已经存在,存在则不继续处理❷。//miner/worker.go:556
w.pendingMu.RLock()
task, exist := w.pendingTasks[sealhash]
w.pendingMu.RUnlock()
if !exist { //❸
continue
}
var (
receipts = make([]*types.Receipt, len(task.receipts))
logs []*types.Log
)
for i, receipt := range task.receipts { //❹
receipt.BlockHash = hash
receipt.BlockNumber = block.Number()
receipt.TransactionIndex = uint(i)
receipts[i] = new(types.Receipt)
*receipts[i] = *receipt
for _, log := range receipt.Logs {
log.BlockHash = hash
}
logs = append(logs, receipt.Logs...)
}也许挖矿任务已被取消,如果Pending Tasks 中不存在区块对应的挖矿任务信息,则说明任务已被取消,就不需要继续处理❸。从挖矿任务中,整理交易回执,补充缺失信息,并收集所有区块事件日志信息❹。//miner/worker.go:584
stat, err := w.chain.WriteBlockWithState(block, receipts, task.state)//
if err != nil {
log.Error("Failed writing block to chain", "err", err)
continue
}
//...
w.mux.Post(core.NewMinedBlockEvent{Block: block})//❻随后,将区块所有信息写入本地数据库❺,对外发送挖出新块事件❻。在 eth 包中会监听并订阅此事件。//eth/handler.go:771
func (pm *ProtocolManager) minedBroadcastLoop() {
for obj := range pm.minedBlockSub.Chan() {
if ev, ok := obj.Data.(core.NewMinedBlockEvent); ok {
pm.BroadcastBlock(ev.Block, true) //❼
pm.BroadcastBlock(ev.Block, false) //❽
}
}
}一旦接受到事件,则立即将广播。首随机广播给部分节点❼,再重新广播给不存在此区块的其他节点❽。//miner/worker.go:595
var events []interface{}
switch stat {
case core.CanonStatTy:
events = append(events, core.ChainEvent{Block: block, Hash: block.Hash(), Logs: logs})
events = append(events, core.ChainHeadEvent{Block: block})
case core.SideStatTy:
events = append(events, core.ChainSideEvent{Block: block})
}
w.chain.PostChainEvents(events, logs)//❾
w.unconfirmed.Insert(block.NumberU64(), block.Hash())//⑩同时,也需要通知程序内部的其他子系统,发送事件。新存储的区块,有可能导致切换链分支。如果变化,则队伍是发送 ChainSideEvent 事件。如果没有切换,则说明新区块仍然在当前的最长链上。对外发送 ChainEvent 和 ChainHeadEvent事件❾。新区块并非立即稳定,暂时存入到未确认区块集中。可这个 unconfirmed 仅仅是记录,但尚未具体使用。总结至此,已经讲解完以太坊挖出一个新区块所经历的各个环节。下面是一张流程图是对挖矿环节的细化,可以边看图便对比阅读此文。同时在讲解时,并没有涉及共识内部逻辑、以及提交交易到虚拟机执行内容。这些内容不是挖矿流程的重点,共识部分将在一下次讲解共识时细说。hi ,我录制了《说透以太坊技术》的视频课程,快快上
ETH 挖矿算法 | 登链社区 | 区块链技术社区
ETH 挖矿算法 | 登链社区 | 区块链技术社区
文章
问答
讲堂
专栏
集市
更多
提问
发表文章
活动
文档
招聘
发现
Toggle navigation
首页 (current)
文章
问答
讲堂
专栏
活动
招聘
文档
集市
搜索
登录/注册
ETH 挖矿算法
Responsibility
更新于 2022-07-01 16:01
阅读 1922
ETH 挖矿算法 :设计目标,莱特币,以太坊解决方案
## ETH 挖矿算法
### 设计目标
中本聪在比特币白皮书中指出区块链的目标是one cpu,one vote, 然而比特币的设计不足导致,简单重复的hash计算挖矿,导致出现了大量的集中矿池采用ASIC矿机,占用了大部分的算力,这与比特币的设计初衷和区块链的去中心化理念背道而驰,因此为了防止出现比特币的ASIC专业矿机,ETH挖矿算法 在设计之初就主要考虑考虑增加内存的需求,而专业矿机在内存上的差距并不大,因此对内存的提升能够有效的避免矿机的出现,于此同时,以太坊也一直考虑采用PoS(proof of stake)权益证明避免算力的集中。
### 莱特币
早起莱特币也考虑了该问题,莱特币提出的解决方案为memory hard,增加对内存的需求,需要存储一个128K(由于对于轻节点来说不够友好,轻节点挖矿本身就不能够存储过大,因此该内存需求又不能够太大,所以只设计了128K)的随机字段的数组来计算nonce
由于设计问题,内存需求较小,且同时通过time memory trade off 来节省一半的内存),所以并没有解决实际问题,但是他的思想理念和早期的宣传还是带来了很大的影响,使得莱特币至今仍流行,莱特币的出块间隔为2分半。
### 以太坊解决方案
以太坊的提出的设计算法为ethash,是指通过设置一大一小的数据集,初始时,其中小的为16M的cache用于验证,轻节点只需要保存这个cache即可对区块的合法性进行验证,大的是通过cache计算生成的1G的dataset,该dataset用于计算nonce,也就是挖矿,只有矿工全节点需要保存该节点,同时这两个数据集都会定期增长来增加对内存的需求。下面是挖矿的整个过程
**cache: 从Seed 计算出第一个数值,然后依次计算哈希填充第二个数,然后依次填充**

**dataset:从cache的尾随机数进行生成 **
lastModify=1656662157)nonce计算:从dataset中读取两个相邻的数,与难度计算得到target范围内的数,下面是挖矿代码
**全部代码**
**同时以太坊也提出了pre-mining 和pre-sale来提前集资为开发工作提供资金**
ETH 挖矿算法
设计目标
中本聪在比特币白皮书中指出区块链的目标是one cpu,one vote, 然而比特币的设计不足导致,简单重复的hash计算挖矿,导致出现了大量的集中矿池采用ASIC矿机,占用了大部分的算力,这与比特币的设计初衷和区块链的去中心化理念背道而驰,因此为了防止出现比特币的ASIC专业矿机,ETH挖矿算法 在设计之初就主要考虑考虑增加内存的需求,而专业矿机在内存上的差距并不大,因此对内存的提升能够有效的避免矿机的出现,于此同时,以太坊也一直考虑采用PoS(proof of stake)权益证明避免算力的集中。
莱特币
早起莱特币也考虑了该问题,莱特币提出的解决方案为memory hard,增加对内存的需求,需要存储一个128K(由于对于轻节点来说不够友好,轻节点挖矿本身就不能够存储过大,因此该内存需求又不能够太大,所以只设计了128K)的随机字段的数组来计算nonce
由于设计问题,内存需求较小,且同时通过time memory trade off 来节省一半的内存),所以并没有解决实际问题,但是他的思想理念和早期的宣传还是带来了很大的影响,使得莱特币至今仍流行,莱特币的出块间隔为2分半。
以太坊解决方案
以太坊的提出的设计算法为ethash,是指通过设置一大一小的数据集,初始时,其中小的为16M的cache用于验证,轻节点只需要保存这个cache即可对区块的合法性进行验证,大的是通过cache计算生成的1G的dataset,该dataset用于计算nonce,也就是挖矿,只有矿工全节点需要保存该节点,同时这两个数据集都会定期增长来增加对内存的需求。下面是挖矿的整个过程
cache: 从Seed 计算出第一个数值,然后依次计算哈希填充第二个数,然后依次填充
dataset:从cache的尾随机数进行生成
lastModify=1656662157)nonce计算:从dataset中读取两个相邻的数,与难度计算得到target范围内的数,下面是挖矿代码
全部代码
同时以太坊也提出了pre-mining 和pre-sale来提前集资为开发工作提供资金
学分: 2
分类: 以太坊
标签:
挖矿
挖矿算法
挖矿难度
点赞 1
收藏 0
分享
Twitter分享
微信扫码分享
你可能感兴趣的文章
CBDC中本聪算力模式系统开发功能实现技术
816 浏览
门罗在线能不能挖RVN渡鸦币
2771 浏览
挖KVA(Kevacoin)币教程(普通windows电脑)
2165 浏览
DeFi安全之杠杆挖矿
1658 浏览
Web3系列教程之入门篇---3:什么是挖矿?
3345 浏览
相关问题
为什么远程挖矿速度远远慢于在geth命令行启动挖矿
1 回答
以太坊私链启动挖矿提示 Error: too many arguments, want at most 0
3 回答
我们需要一位有加密货币软件经验的开发者
0 回答
不小心双击了geth.exe算是挖矿?什么行为算是在挖矿?
3 回答
在用代码进行挖矿的时候,进行哈希运算的时候为什么一定要先转换成json格式,并且还要排序?
1 回答
0 条评论
请先 登录 后评论
Responsibility
关注
贡献值: 40
学分: 41
江湖只有他的大名,没有他的介绍。
文章目录
关于
关于我们
社区公约
学分规则
Github
伙伴们
DeCert
ChainTool
GCC
合作
广告投放
发布课程
联系我们
友情链接
关注社区
Discord
Youtube
B 站
公众号
关注不错过动态
微信群
加入技术圈子
©2024 登链社区 版权所有 |
Powered By Tipask3.5|
粤公网安备 44049102496617号
粤ICP备17140514号
粤B2-20230927
增值电信业务经营许可证
×
发送私信
请将文档链接发给晓娜,我们会尽快安排上架,感谢您的推荐!
发给:
内容:
取消
发送
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
取消
举报
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!